Performance Corner: Small Changes Pack a Punch
Here we have another round of changes to make packages smaller and show just how much we care about performance and
efficiency! Today we are focusing mainly on moss-format changes to reduce the size of its payloads. The purpose of
these changes is to reduce the size of packages, DB storage for transactions and memory usage for moss. These changes
were made just before we moved out of bootstrap, so we wouldn't have to rebuild the world after changing the format.
Lets get started!
Squeezing Out the Last Blit of Performance
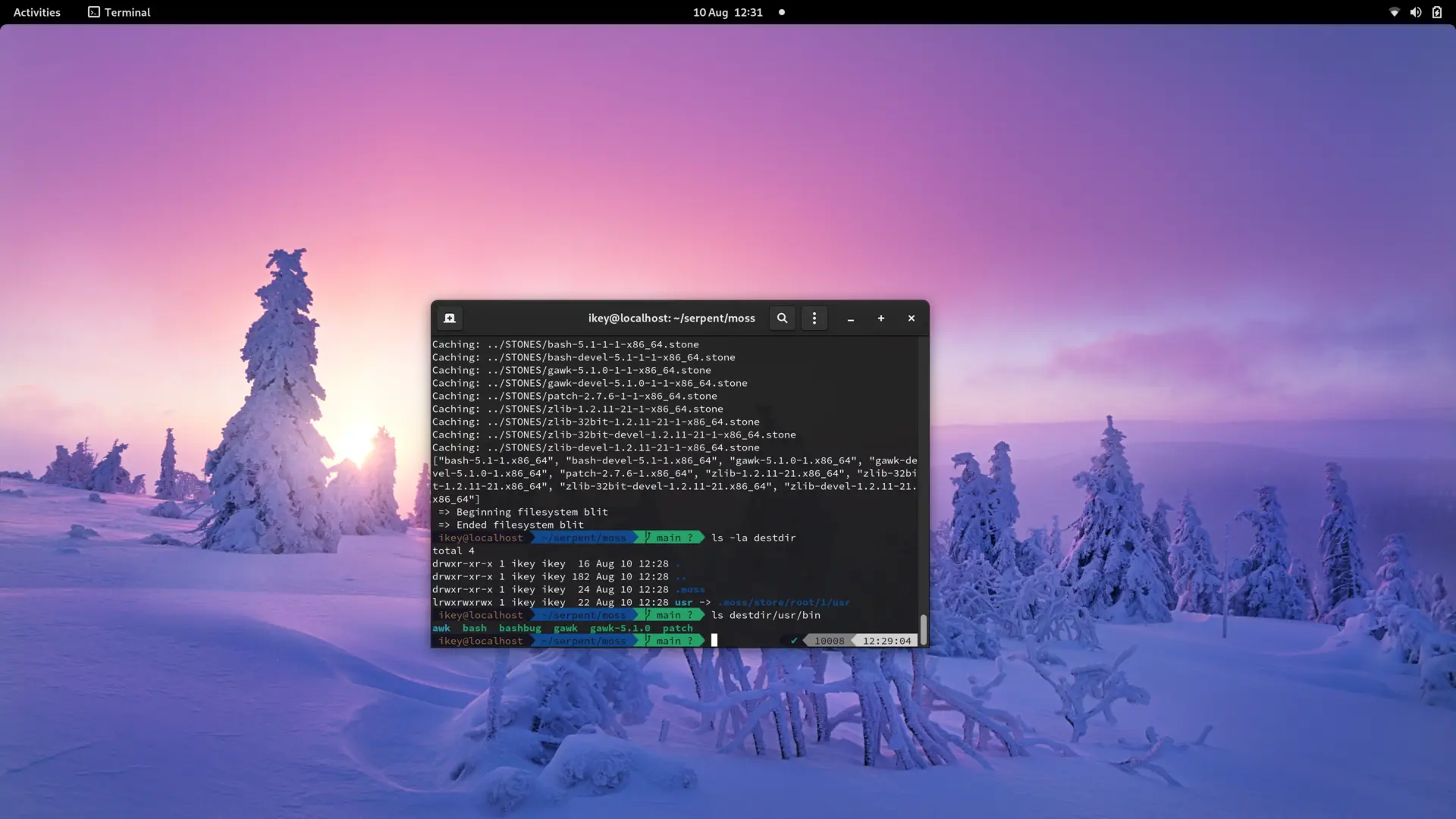
Blitting in Serpent OS is the process of setting up a root, using hardlinks of files installed in the moss store to
construct the system /usr directory. Some initial testing showed buildPath using about 3% of the total events
when installing a package with many files. As a system is made up of over 100,000 files, that's a lot of paths that need
to be calculated! Performance is therefore important to minimize time taken and power consumed.
After running a few benchmarks of buildPath, there were a few tweaks which could improve the performance. Rather than
calculating the full path of the file, we can reuse the constant root path for each file instead, reducing buildPath
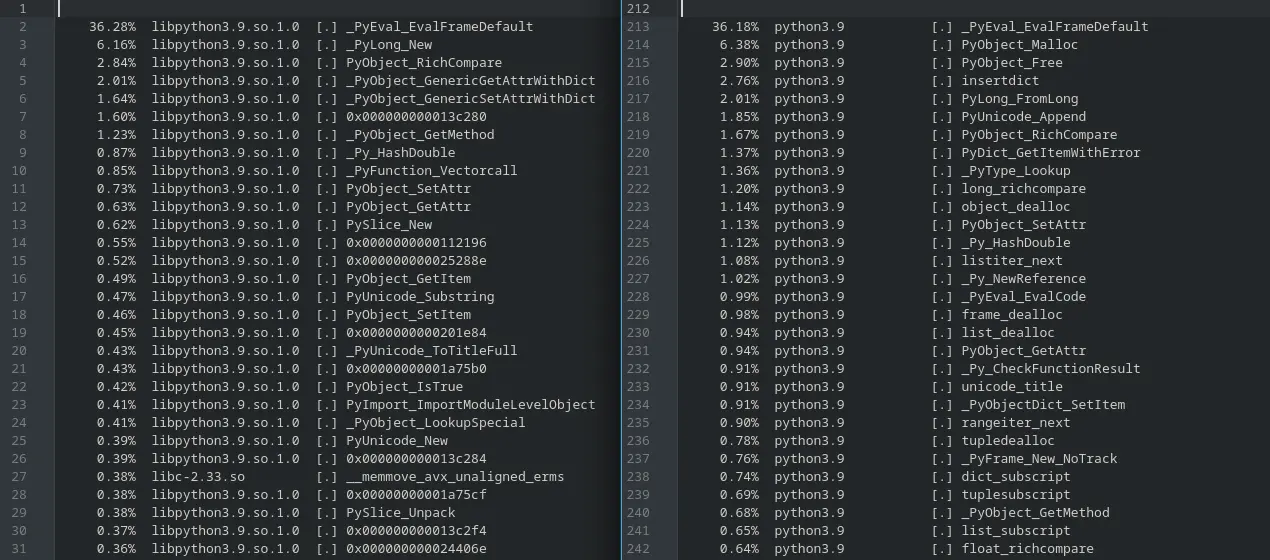
events by 15%. Here we see some callgrind data from this small change (as it was difficult to pickup in the noise).
Before:
48,766,347 ( 1.50%) /usr/include/dlang/ldc/std/path.d:pure nothrow @safe immutable(char)[] std.path.buildPath
34,241,805 ( 1.05%) /usr/include/dlang/ldc/std/utf.d:pure nothrow @safe immutable(char)[] std.path.buildPath
14,363,684 ( 0.44%) /usr/include/dlang/ldc/std/range/package.d:pure nothrow @safe immutable(char)[] std.path.buildPath
After:
40,357,800 ( 1.25%) /usr/include/dlang/ldc/std/path.d:pure nothrow @safe immutable(char)[] std.path.buildPath
29,523,966 ( 0.91%) /usr/include/dlang/ldc/std/utf.d:pure nothrow @safe immutable(char)[] std.path.buildPath
12,814,283 ( 0.40%) /usr/include/dlang/ldc/std/range/package.d:pure nothrow @safe immutable(char)[] std.path.buildPath
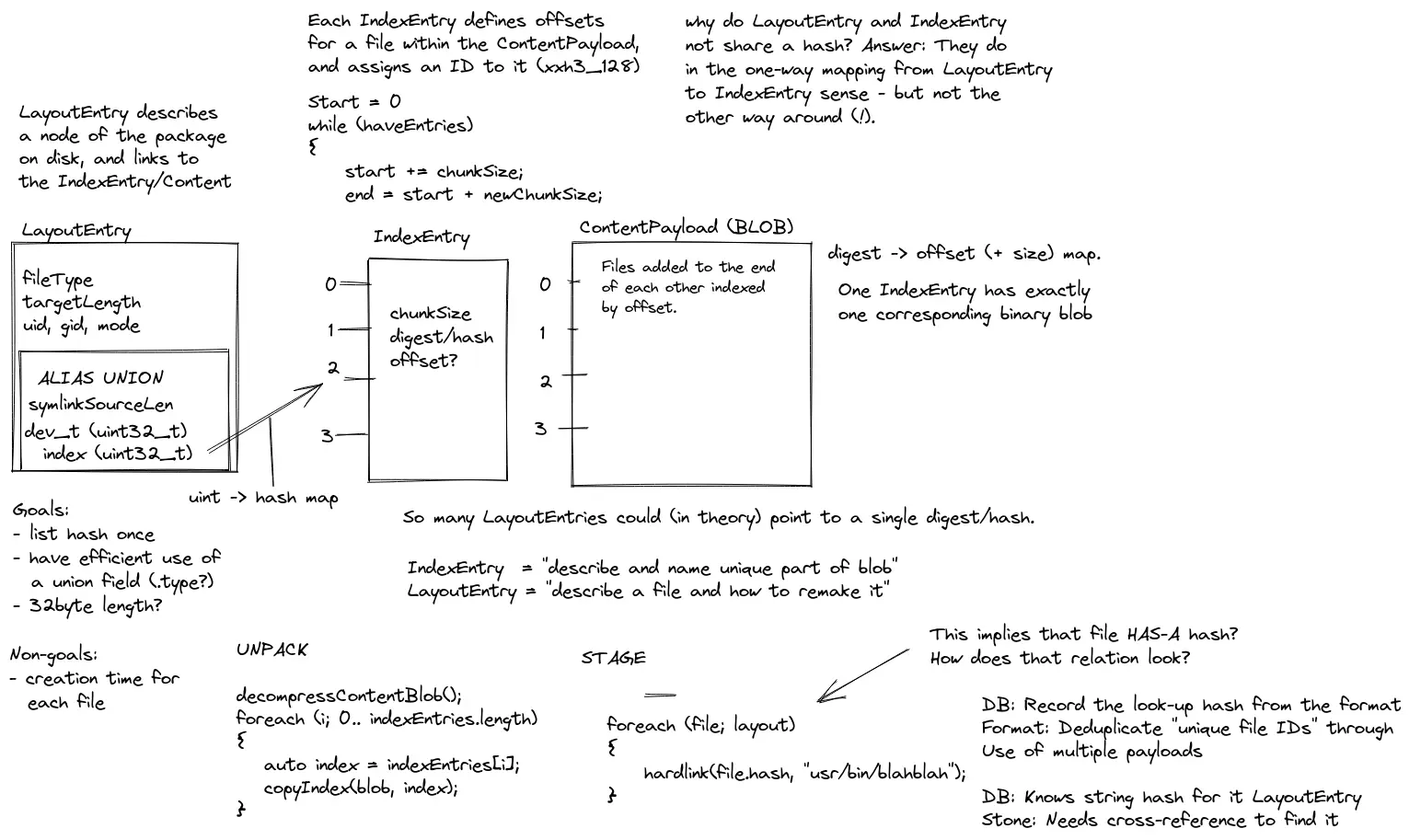
Only Record What's Needed!
Our Index Payload is used for extracting the Content Payload into its hashed file names. As it has one job (and then
discarded), we could hone in on including only the information we needed. Previously an entry was a 32 byte key and
storing a 33 byte hash. We have now integrated the hash as a ubyte[16] field, cut other unneeded fields so that we can
fit the whole entry into 32 bytes. That's a 51% reduction in the size of the Index Payload and about 25% smaller when
compressed.
Before: Index [Records: 3688 Compression: Zstd, Savings: 60.61%, Size: 239.72 KB]
After: Index [Records: 3688 Compression: Zstd, Savings: 40.03%, Size: 118.02 KB]
Too Many Entries Makes for a Large Payload
One of the bugbears about the Layout Payload, was the inclusion of Directory paths for every single directory. This is
handy in that directories can be created easily before any files are included (to ensure they exist), but it comes at a
price. The issue was twofold, the extra entries made inspecting the file list take longer and also made the Layout
Payload larger than it needed to be. Therefore directories are no longer included as Layout entries with the exceptions
of empty directories and directories with different permissions. Lets compare nano and glibc builds before and
after the change:
nano
Before: Layout [Records: 174 Compression: Zstd, Savings: 80.58%, Size: 13.78 KB]
After: Layout [Records: 93 Compression: Zstd, Savings: 73.49%, Size: 9.15 KB]
glibc
Before: Layout [Records: 7879 Compression: Zstd, Savings: 86.88%, Size: 755.00 KB]
After: Layout [Records: 6813 Compression: Zstd, Savings: 86.24%, Size: 689.20 KB]
A surprisingly large impact from a small change, with 1,000 fewer entries for glibc and cutting the Layout Payload
size of nano by a third. What it shows is that it's hugely beneficial where locales are involved and % size reduction
increases where you have fewer files. To give an example of how bad it could be, the KDE Frameworks package
ktexteditor would have produced 300 entries in the Layout Payload, where 200 of those would have been for directories!
I'd estimate a 50% reduction in the Layout Payload size for this package! Here's an example of how a locale file used
to be stored (where only the last line is added now).
- /usr/share/locale [Directory]
- /usr/share/locale/bg [Directory]
- /usr/share/locale/bg/LC_MESSAGES [Directory]
- /usr/share/locale/bg/LC_MESSAGES/nano.mo -> ec5b82819ec2355d4e7bbccc7d78ce60 [Regular]
This will be exceptionally useful for keeping the LayoutDB slimmer and faster as the number of packages grows.
Cutting Back 1 Byte at a Time
Next we removed recording the timestamps of files, which for reproducible builds, is often a number of little relevance
as you have to force them all to a fixed number. As moss is de-duplicating for files, there's a second issue where two
packages could have different timestamps for the same hash. Therefore it was considered an improvement to simply exclude
timestamps altogether. This improved install time as we no longer overwrite the timestamps and made the payload more
compressible due to replacing it with 8 bytes of padding. Unfortunately we weren't quite able to free up 16 bytes to
reduce the size of each entry, but will be something to pursue in future.
Another quick improvement was reducing the lengths of paths for each entry. moss creates system roots and switches
between them by changing the /usr symlink. Therefore, all system files need to be installed into /usr or they will
not make up your base system. Therefore we have no need to store /usr in the Payload so we strip /usr/ from the
paths (the extra / gives us another byte off!) which we recreate on install. This improved the uncompressed size of the
Payload, with only a minor reduction when compressed.
Combined these result in about a 5% decrease in the compressed and uncompressed size of the Layout Payload.
Before: Layout [Records: 6812 Compression: Zstd, Savings: 86.24%, Size: 689.10 KB]
After: Layout [Records: 6812 Compression: Zstd, Savings: 86.20%, Size: 655.00 KB]
Storing the Hash Efficiently
Using the same method for the Index Payload, we are now storing the hash as ubyte[16], but not directly in the
Payload Entry. This gives us a sizeable reduction of 17 bytes per entry which is the most significant of all the
Layout Payload changes. As the extra space was unneeded, it compressed well so only resulted in a small reduction in
the compressed Payload size.
Before: Layout [Records: 6812 Compression: Zstd, Savings: 86.20%, Size: 655.00 KB]
After: Layout [Records: 6812 Compression: Zstd, Savings: 83.92%, Size: 539.26 KB]
Hang On, Why am I Getting Faster Installation?
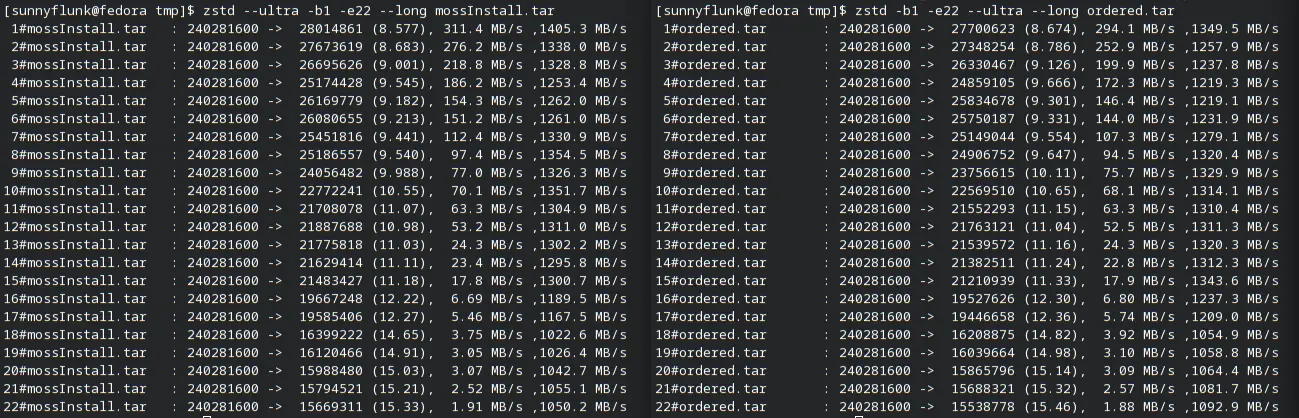
As a side-effect of small code rewrites to implement these changes, we've seen a nice decrease in time to install
packages. There are fewer entries to iterate over with the removal of directories and buildPath is now only called
once for each path. It goes to show that focusing on the small details leads to less, more efficient and faster code.
Here we find that we have now essentially halved the number of events related to buildPath with all the changes
resulting in about a 5% reduction in install time. Note that for this test, over 80% of time is spent in zstd
decompressing the package which we haven't optimized (yet!). Here's another look the buildPath numbers factoring in
all the changes:
Before:
48,766,347 ( 1.50%) /usr/include/dlang/ldc/std/path.d:pure nothrow @safe immutable(char)[] std.path.buildPath
34,241,805 ( 1.05%) /usr/include/dlang/ldc/std/utf.d:pure nothrow @safe immutable(char)[] std.path.buildPath
14,363,684 ( 0.44%) /usr/include/dlang/ldc/std/range/package.d:pure nothrow @safe immutable(char)[] std.path.buildPath
After:
25,145,625 ( 0.79%) /usr/include/dlang/ldc/std/path.d:pure nothrow @safe immutable(char)[] std.path.buildPath
17,967,216 ( 0.57%) /usr/include/dlang/ldc/std/utf.d:pure nothrow @safe immutable(char)[] std.path.buildPath
7,761,417 ( 0.24%) /usr/include/dlang/ldc/std/range/package.d:pure nothrow @safe immutable(char)[] std.path.buildPath
Summing it All Up
It was a pretty awesome weekend of work (a few weeks ago now), making some quick changes that will improve Serpent OS
a great deal for a long time to come. This also means we have integrated all the quick format changes so we won't have
to rebuild packages while bringing up the repos.
Here's a quick summary of the results of all these small changes:
- 51% reduction in the uncompressed size of the Index Payload
- 25% reduction in the compressed size of the Index Payload
- 29-50% reduction in the uncompressed size of the Layout Payload (much more with fewer files and more locales)
- 12-15% reduction in the compressed size of the Layout Payload
- 5% faster package installation for our benchmark (800ms to 760ms)
These are some pretty huge numbers and even excluded the massive improvements we made in the previous blog!
What if We Include the Previous Changes?
I'm glad you asked, cause I was curious too! Here we see a before and after with all the changes included. For the
Layout Payload we see a ~45% reduction in the compressed and uncompressed size. For the Index Payload we have
reduced the uncompressed size by 67% and the compressed size by 56%. Together resulting in halving the compressed and
uncompressed size of the metadata of our stone packages!
Before:
Payload: Layout [Records: 5441 Compression: Zstd, Savings: 83.13%, Size: 673.46 KB] (113.61 KB compressed)
Payload: Index [Records: 2550 Compression: Zstd, Savings: 55.08%, Size: 247.35 KB] (111.11 KB compressed)
After:
Payload: Layout [Records: 4718 Compression: Zstd, Savings: 83.62%, Size: 374.42 KB] (61.33 KB compressed)
Payload: Index [Records: 2550 Compression: Zstd, Savings: 39.85%, Size: 81.60 KB] (49.01 KB compressed)
Now we proceed towards bringing up repos to enjoy our very efficient packages!