Enough of this "2 years" nonsense. We're finally ready for lift off. It is with immense pleasure we can
finally announce that Serpent OS has transitioned from a promise to a deliverable. Bye bye, phantomware!
As mentioned, we spent 2 years working on tooling and process. That's .. well. Kinda dull, honestly. You're
not here for the tooling, you're here for the OS. To that end I made a decision to accelerate development of
the actual Linux distro - and shift development of tooling into a parallel effort.
I deferred final enabling of the infrastructure until January to rectify the chicken/egg scenario whilst allowing
us to grow a base of contributors and an actual distro to work with. We're in a good position with minimal blockers
so no concern there.
This is our term for the classical "package repository". We're using a temporary collection right now to store all
of the builds we produce. In keeping with the Avalanche requirements, this is the volatile software collection. Changes
a lot, hasn't got a release policy.
It goes without saying, really, that our project isn't remotely possible without a community. I want to take the time
to personally thank everyone that stepped up to the plate lately and contributed to Serpent OS. Without the work of the
team, in which I include the contributors to our venom recipe repository, an ISO was never possible. Additionally contributions
to tooling has helped us make significant strides.
It should be noted we've practically folded our old "team" concept and ensured we operate across the board as a singular community,
with some members having additional responsibilities. Our belief is all in the community have equal share and say. With that said,
to the original "team", members both past and present, I thank for their (long) support and contributions to the project.
We actually went ahead and created our first ISO. OK that's a lie, this is probably the 20th revision by now. And let's be brutally
honest here:
It sucks.
We expected no less. However, the time is definitely here for us to begin our public iteration, transitioning from suckness to a project
worth using. In order to do that, we need to get ourselves to a point whereby we can dogfood our work and build a daily driver. Our focus
right now is building out the core technology and packaging to achieve those aims.
So if you want to try our uninstallable, buggy ISO, chiefly created as a brief introduction to our package manager and toolchain, head to our
newly minted Download page. Set your expectations low, ignore your dreams, and you will not be disappointed!
All jokes aside, it took a long time to get to point where we could even construct our first, KVM-focused, UEFI-only snekvalidator.iso. We now
have a baseline to improve on, a working contribution process, and a booting, self-hosting system.
The ISO is built using 2 layered collections, the protosnek collection containing our toolchain, and the new volatile collection. Much of the
packaging work has been submitted by venom contributors and the core team. Note you can install neofetch which our very own Rune Morling (ermo)
patched to support the Serpent OS logo.
Boot it in Qemu (or certain Intel laptops) and play with moss now! Note, this ISO is not installable, and no upgrade path exists. It is simply
the beginnings of a public iteration process.
In January we'll launch our infrastructure to scale out contributions as well as to permit the mass-rebuilds that need to happen. We have to
enable our -dbginfo packages and stripping, which were disabled due to a parallelism issue. We need to introduce our boot management based around
systemd-boot, provide more kernels, do hardware enabling, introduce moss-triggers, and much more. However, this is a pivotal moment for our
project as we've finally become a real, if not sucky, distro. The future is incredibly bright, and we intend to deliver on every one of our
promises.
As always, if you want to support our development, please consider sponsoring the work, or engaging with the community on Matrix or indeed
our forums.
You can discuss this blog post, or leave feedback on the ISO, over at our forums.
After much deliberation - we've decided to pull out of Open Collective. Among other reasons, the fees
are simply too high and severely impact the funds available to us. In our early stages, the team consensus
is that funds generated are used to compensate my time working on Serpent OS.
As such I'm now moving funding to my own GitHub Sponsors page - please do migrate! It ensures your entire
donation makes it and keeps the lights on for longer =) Please remember I'm working full time on Serpent OS
exclusively - I need your help to keep working.
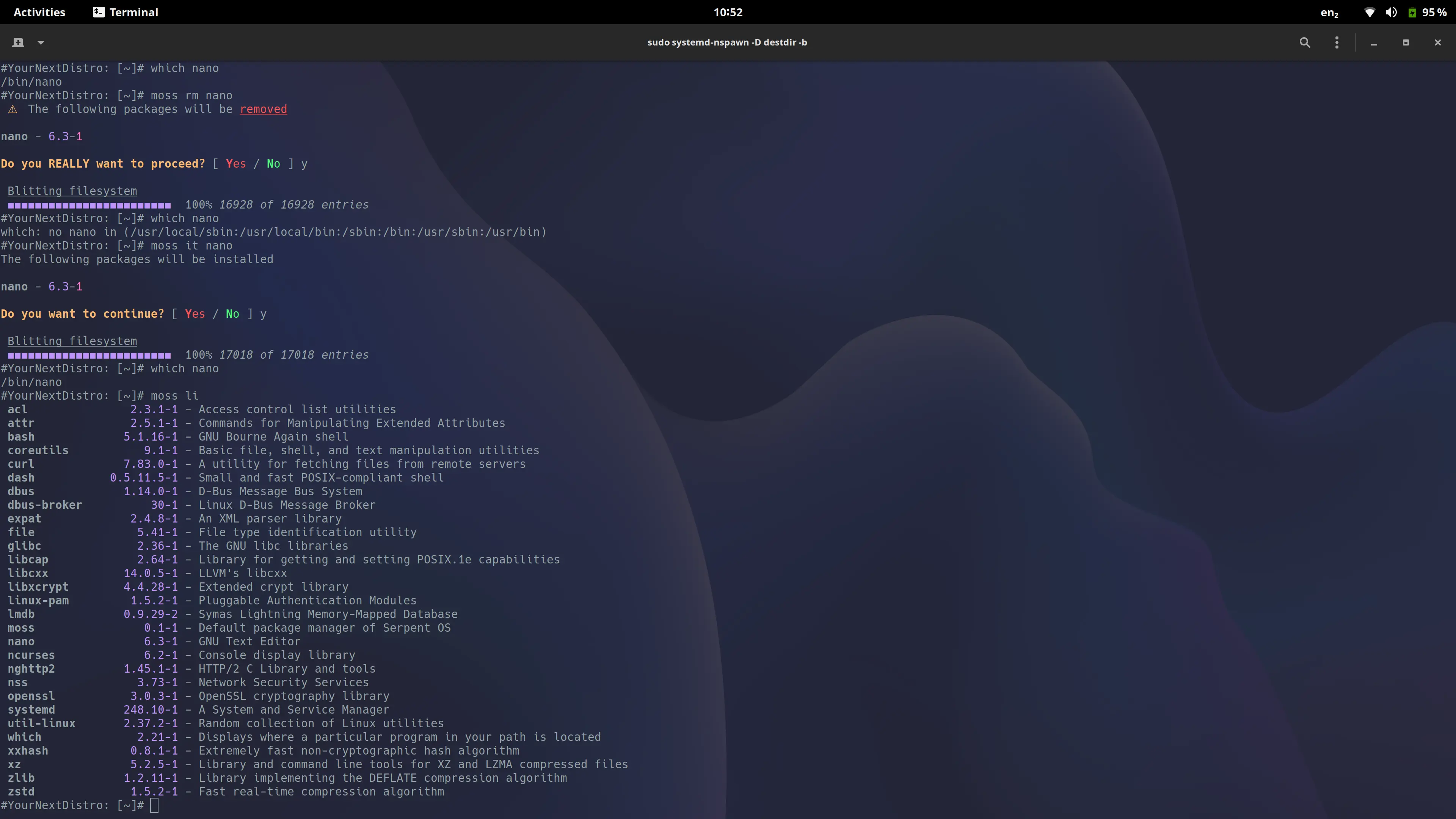
On the surface, moss looks and feels roughly the same as just about any other traditional package manager out there.
Internally, however, its far more modern and has a few tricks up its sleeve. For instance, every time you initiate
an operation in moss, be it installation, removal, upgrade, etc, a new filesystem transaction is generated. In short,
if something is wrong with the new transaction - you can just boot to an older transaction when things worked fine.
Now, it's not implemented using bundles or filesystem specific functionality, internally its just intelligent use of
hardlinks and deduplication policies, and we have our own container format with zstd based payload compression. Our
strongly typed, deduplicating binary format is what powers moss.
Behind the scenes we also use some other cool technology, such as LMDB for super reliable and speedy database access.
The net result is a next generation package management solution that offers all the benefits of traditional package
managers (i.e. granularity and composition) with new world features, like atomic updates, deduplication, and repository
snapshots.
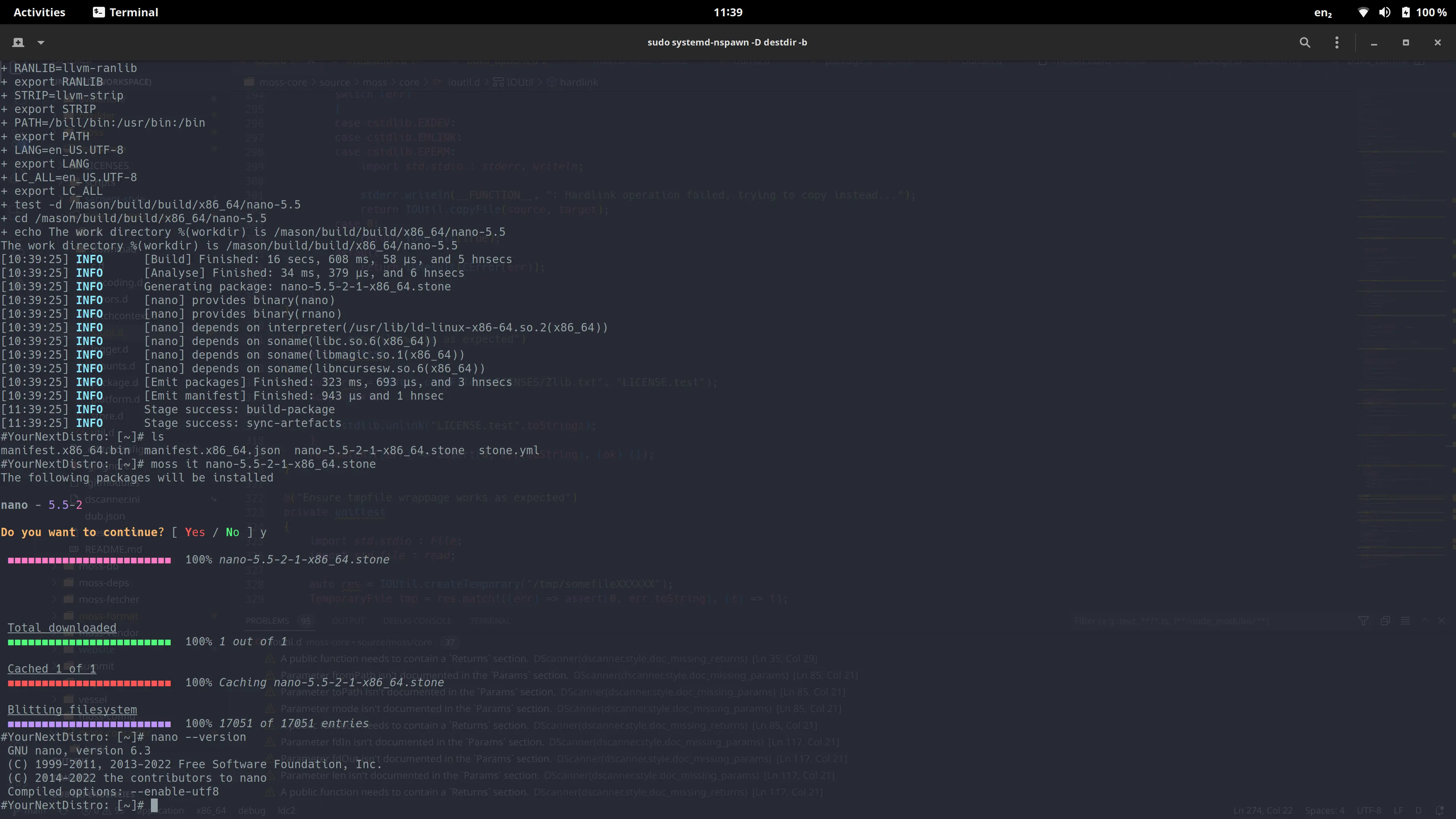
It's one thing to manage and install packages, it's another entirely to build them. boulder builds conceptually
on prior art such as pisi and the package.yml format used in ypkg. It is designed with automation
and ease of integration in mind, i.e. less time spent focusing on packaging and more time on actually
getting the thing building and installing correctly.
Boulder supports "macros" as seen in the RPM and ypkg world, to support consistent builds and integration.
Additionally it automatically splits up packages into the appropriate subpackages, and automatically scans
for binary, pkgconfig, perl and other dependencies during source analysis and build time. The end result
is some .stone binary packages and a build manifest, which we use to flesh out our source package index.
We've spent considerable time reworking moss, our package manager. It now features
a fresher (terminal) user interface, progress bars, and is rewritten to use the
moss-db module encapsulating LMDB.
It's also possible to manipulate the binary collections (software repositories)
used by moss now. Note we're going to rename "remote" to "collection" for consistency.
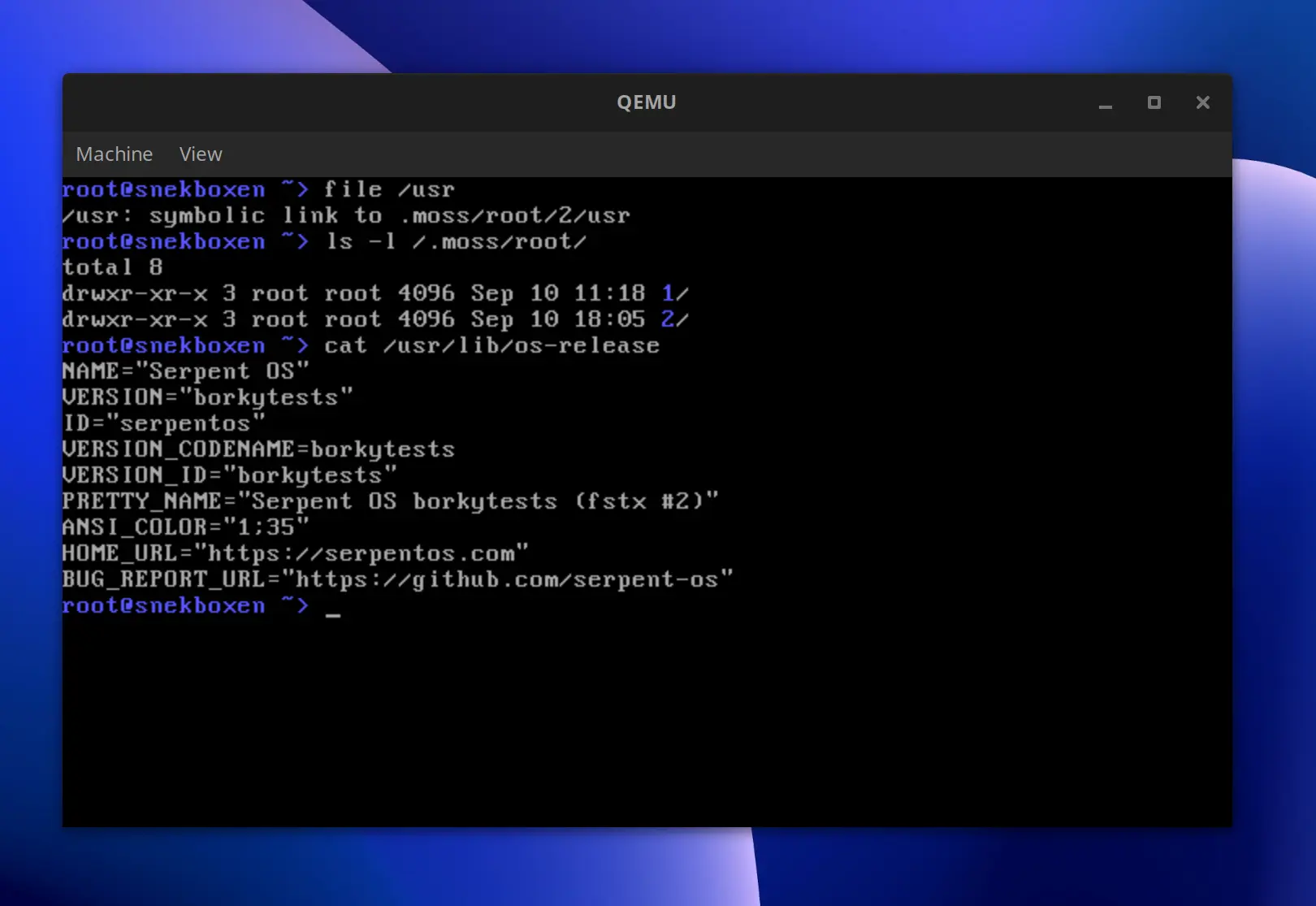
Serpent OS is now officially self hosting. Using our own packages, we're able to
construct a root filesystem, then within that rootfs container we can use our own
build tooling (boulder) to construct new builds of our packages in a nested
container.
The protosnek collection has been updated to include the newest versions of moss
and boulder.
As a fun experiment, we wanted to see how far along things are. Using a throwaway
kernel + initrd build, we were able to get Serpent OS booting using virtualisation (qemu)
Right now everyone is working in the snekpit organisation to
get our base packaging in order. I'm looking to freeze protosnek, our bootstrap collection,
at the latest of tomorrow evening.
We now support layered, priority based collections (repositories) and dependency solving across
collection boundaries, allowing us to build our new main collection with protosnek acting as
a bootstrap seed.
Throughout this week, I'll focus on getting Avalanche, Summit and Vessel into shape for PoC so
that we can enjoy automated builds of packages landing in the yet-to-be-launched volatile collection.
From there, we're going to iterate + improve packaging, fixing bugs and landing features as we
discover the issues. Initially we'll look to integrate triggers in a stateless-friendly
fashion (our packages can only ship /usr by design) - after that will come boot management.
An early target will be Qemu support via a stripped linux-kvm package to accelerate the bring up,
and we encourage everyone to join in the testing. We're self hosting, we know how to boot, and
now we're able to bring the awesome.
I cannot stress how important the support to the project is. Without it - I'm unable to work full
time on the project. Please consider supporting my development work via GitHub Sponsors.
I'm so broke they've started naming black holes after my IBAN.
Since the last post, I've pivoted to full time work on Serpent OS, which is
made all the more possible thanks to everyone supporting us via OpenCollective <3.
We've been working towards establishing an online infrastructure to support the automation of package builds, while
revisiting some core components.
During the development of the Serpent OS tooling we've been exploring the possibilities of D Lang, picking up new
practices and refining our approach as we go. Naturally, some of our older modules are somewhat ... smelly.
Most noticeable is our moss-db module, which was initially intended as a lightweight wrapper around RocksDB.
In practice that required an encapsulation API written in D around the C API, and our own wrapping on top of that. Naturally,
it resulted in a very allocation-heavy implementation that just didn't sit right with us, and due to the absurd complexity
of RocksDB was still missing quite a few features.
We're now using the Lightning Memory-Mapped Database as the driver implementation
for moss-db. In short, we get rapid reads, ACID transactions, bulk inserts, you name it. Our implementation takes
advantage of multiple database indexes (MDB_dbi) in LMDB to partition the database into internal components,
so that we can provide "buckets", or collections. These internal DBs are used for bucket mapping to permit a
key-compaction strategy - iteration of top level buckets and key-value pairs within a bucket.
The majority of the API was designed with the boltdb API in mind. Additionally
it was built with -preview=dip1000 and -preview=in enabled, ensuring safely scoped memory use and no
room for memory lifetime issues. While we prefer the use of generics, the API is built with immutable(ubyte[])
as the internal key and value type.
Custom types can simply implement mossEncode or mossDecode to be instantly serialisable into the database
as keys, values or bucket identifiers.
Example API usage:
Databasedb;/* setup the DB with lmdb:// URI *//* Write transaction */autoerr=db.update((scopetx)@safe{autobucket=tx.bucket("letters");returntx.set(bucket,"a",1);});/* do something with the error */err=db.view((intx)@safe{foreach(name,bucket;tx.buckets!int){foreach(key,value;tx.iterator!(string,string)(bucket)){/* do something with the key value pairs, decoded as strings */}}/* WILL NOT COMPILE. tx is const scope ref :) */tx.removeBucket("numbers");returnNoDatabaseError;}
Moss will be ported to the new DB API and we'll gather some performance metrics,
while implementing features like expired state garbage collection (disk cleanup),
searching for names/descriptions, etc.
Avalanche is a core component of our upcoming infrastructure, providing the
service for running builds on a local node, and a controller to coordinate
a group of builders.
Summit will be the publicly accessible project dashboard, and will be responsible
for coordinating incoming builds to Avalanche controllers and repositories.
Developers will submit builds to Summit and have them dispatched correctly.
So far we have the core service process in place for the Controller + Node,
and now we're working on persistence and handshake. TLDR; fancy use of
moss-db and JSON Web tokens over mandated SSL. This means our build infra
will be scalable from day 1 allowing multiple builders to be online very
early on.
Hot damn we've been busy lately. No, really.
The latest development cycle saw us focus exclusively on boulder, our build tooling. As of
today it features a proof of concept boulder new subcommand for the automatic generation of
packaging templates from an upstream source (i.e. tarball).
Before we really start this blog post off, I'd like to thank everyone who is supporting the
project! All of the OpenCollective contributions will make it easier for me to work full
time on Serpent OS =) Much love <3
Alright you got me there, certain projects prefer to abstract the configuration, build and
installation of packages and be provided with some kind of hint to the build system, i.e.
manually setting autotools, etc.
Serpent OS packaging is declarative and well structured, and relies on the use of RPM-style
"macros" for distribution integration and common tasks to ensure consistent packaging.
We prefer a self documenting approach that can be machine validated rather than depending
on introspection at the time of build. Our stone.yml format is very flexible and powerful,
with automatic runtime dependencies and package splitting as standard.
..Doesn't mean we can't make packaging even easier though.
Pointing boulder at an upstream source will perform a deep analysis of the sources to determine
the build system type, build dependencies, metadata, licensing etc. Right now it's just getting
ready to leave POC stage so it has a few warts, however it does have support for generating
package skeletons for the following build systems:
cmake
meson
autotools
We're adding automation for Perl and Python packaging (and Golang, Rust, etc) so we can enforce consistency,
integration and ease without being a burden on developers. This will greatly reduce the friction
of contribution - allowing anyone to package for Serpent OS.
We're also able to automatically discover build time dependencies during analysis and add those
to the skeleton stone.yml file. We'll enhance support for other build systems as we go, ensuring
that each new package is as close to done on creation as possible, with review and iteration left
to the developer.
A common pain in the arse when packaging for any Linux distribution is ensuring the package
information is compliant in terms of licensing. As such we must know all of the licensing
information, as well as FSF and OSI compliance for our continuous integration testing.
...Finding all of that information is truly a painful process when conducted manually.
Thankfully boulder can perform analysis of all licensing files within the project to
greatly improve compliance and packaging.
Every license listed in a stone.yml file must use a valid SPDX identifier,
and be accurate. boulder now scans all license files, looking for matches with both SPDX IDs
as well as fuzzy-matching the text of input licenses to make a best-guess at the license ID.
This has so far been highly accurate and correctly identifies many hundreds of licenses,
ensuring a compliant packaging process with less pain for the developers. Over time we'll
optimise and improve this process to ensure compliance for our developers rather than
blocking them.
As of today we support the REUSE specification for expressing software licenses too!
Work formally begins now on Bootstrap Bill (Turner). Whilst we did successfully bootstrap Serpent OS
and construct the Protosnek repository, the process for that is not reproducible as boulder
has gone through massive changes in this time.
The new project will leverage boulder and a newly
designed bootstrap process to eliminate all host contamination and bootstrap Serpent OS from
stone.yml files, emitting an immutable bootstrap repository.
Layering support will land in moss and boulder to begin the infrastructure projects.
The aim is to complete bill in a very short time so we can bring some initial infrastructure
online to facilitate the automatic build of submitted build jobs. We'll use this process
to create our live repository, replacing the initial bootstrap repository from bill.
At this point all of the tooling we have will come together to allow us all to very
quickly iterate on packaging, polish up moss and race towards installed systems with
online updates.
Well well, it's been a long time since I personally wrote a post.. :) So let's keep
this short and sweet, shall we? I'm returning to full time work on Serpent OS.
The 6th of July will be my last day at my current employment having tendered my
30 day notice today. Despite having enjoyment at my current position, the reality
is that my passion and focus is Serpent OS.
I'm now in a transition process and will ramp up my efforts with Serpent OS.
Realistically I need to reduce the outgoing costs of the project and with
your help I can gain some level of financial support as we move through the
next stages of development. Worst case, I will only take on any part-time or
contractual gigs, allowing my primary focus to be Serpent OS.
I'll begin accelerating works and enabling community contribution so we can
get the derailed-alpha train back on the tracks.
I have absolute faith in this project, the community and our shared ability
to deliver the OS and tooling. To achieve it will require far more of my time
and I'm perfectly willing to give it.
Thank you all to everyone who has been supporting the project, it is now
time to deliver. Not just another run of the mill distribution but a technically
competent and usable distribution that is not only different but better.
Let's do this in the most grassroots and enjoyable way possible =)
RELR is an efficient method of storing relative relocations (but is not yet available in glibc upstream). This has a
significant reduction on file size often in the vicinity of 5% for libraries and even higher for PIE binaries. We also
take a look at the performance impact on enabling RELR and that looks really good too! Smaller files with more
performance - you can have your cake and eat it too!
Everyone enjoys smaller files, especially when it's for free! RELR provides a very efficient method of storing
relative relocations where it only requires a few percent compared to storing them in the .rela.dyn section which is
what currently happens. However, it can't store everything so the .rela.dyn section remains (though much smaller).
Here's an example of the sections of libLLVM-13.so with and without RELR. Here we see the .rela.dyn section taking
up a whole 2MB! When enabling RELR, .rela.dyn shrinks down to just under 100KB while adding a new section
.relr.dyn which is just over 20KB! That's nearly a 1.9MB file size reduction, so you'll get smaller packages, smaller
updates and it will be even faster to create delta packages from our servers. For reference, some of the biggest files
have a .rela.dyn section over 10MB!
While most of the discussion about RELR is around the size savings, there's been very little in terms of the
performance numbers of enabling RELR. For most things, it's not going to make a noticeable difference, as it should
only really impact loading of binaries. There's one rule we have and that's to measure everything! We care about every
little detail where many 1-2% improvements can add up to significant gains.
First, we require a test to determine if we could detect changes between an LLVM built with RELR and one without.
The speed of the compiler is vital to a distro, where lackluster performance of the build system hurts all contributors
and anyone performing source based builds. clang in this example was built using a shared libLLVM so that it would
load the RELR section and it's large enough to be able to measure a difference in load times (if one exists). Building
gettext was the chosen test (total time includes tarball extraction, configure, make and make install stages), rather
than a synthetic binary loading test to reflect real world usage. The configure stage is very long when building
gettext so clang is called many times for short compiles. Lets take a look at the results:
Here we see the base configuration was able to build gettext in 117.21s on average. When we enabled RELR in our
LLVM build (all other packages were without RELR still), the average build time decreased by 1.74s! That does not
sound like a lot, but the time spent loading clang would only be a portion of the total, yet still gives a 1-2%
performance lift over the whole build. While we were reducing start up time, I ran another test, but this time adding a
patch to reduce paths searched on startup as well as enabling RELR. This patch reduced the average build time by a
further 0.63s!
That's a 2.37s reduction in the build just from improving the clang binary's load time.
So what actually is RELR? I can't really do the topic justice, so will point you to a great blog post about RELR,
Relative Relocations and RELR. It's quite technical
for the average reader, but definitely worth a read if you like getting into the details. To no surprise the author
(Fangrui Song) started the initial push for getting RELR support upstream in glibc (at the time of this post the
patch series has not yet been committed to glibc git).
What I can tell you, is that we've applied the requisite patches for RELR support and enabled RELR by default in
boulder for builds. Our container has been rebuilt and all is working well with RELR enabled. More measurements will
be done in future in the same controlled manner, particularly around PIE load times.
The performance benchmark was quite limited in terms of being an optimal case for RELR as clang is called thousands
of times in the build so on average improved load time by about 0.6-0.7ms. We can presume that using RELR on smaller
files is unlikely to regress load times. It definitely gives us confidence that it would be about the same or better in
most situations, but not noticeable or measurable in most use cases. Minimizing build times is a pretty significant
target for us, so even these small gains are appreciated.
The size savings can vary between packages and not everything can be converted into the .relr.dyn section. The current
default use of RELR is not without cost as it adds a version dependency on glibc. We will ensure we ship a sane
implementation that minimizes or removes such overhead.
It was also not straight forward to utilize RELR in Serpent. The pending upstream glibcpatch series included a patch which caused
issues when enabling RELR in Serpent OS (patch 3/5). As we utilize two toolchains, gcc/bfd and clang/lld, both
need to function independently to create outputs of a functional OS. However the part "Issue an error if there is a
DT_RELR entry without GLIBC_ABI_DT_RELR dependency nor GLIBC_PRIVATE definition." meant that glibc would refuse to
load files linked by lld despite having the ability to load them. lld has supported RELR for some time already,
but does not create the GLIBC_ABI_DT_RELR dependency that is required by glibc. I have added my
feedback to the patch set upstream. lld now has
support for this version dependency upstream if we ever decide to use it in future.
After dropping the patch and patching bfd to no longer generate the GLIBC_ABI_DT_RELR dependency either, I was
finally able to build both glibc and LLVM with the same patches. With overcoming that hurdle, rebuilding the rest of
the repository went without a hitch, so we are now enjoying RELR in all of our builds and is enabled by default.
There is even further scope for more size savings, by switching the rela.dyn section for the rel.dyn section (this
is what is used for 32-bit builds and one of the reasons files are smaller!). lld supports switching the section type,
but I don't believe glibc will read the output as it expects the psABI specified section (something musl can
handle though).
A quick check of two equivalent builds (one adding the GLIBC_ABI_DT_RELR version dependency and one not), there was an
increase of 34 bytes to the file's sections (18 bytes to .dynstr and 16 bytes to .gnu.version_r). It also means
having to validate that the GLIBC_ABI_DT_RELR version is present in the libc and that the file using RELR includes
this version dependency. This may not sound like much but it is completely unnecessary! Note that the testing provided
in this blog post is without GLIBC_ABI_DT_RELR.
Regardless of what eventuates, these negatives won't ship in Serpent OS. This will allow for us to support files that
include the version dependency (when appimage and other distros catch up) as it will still exist in libc, but we won't
have the version check in files, nor will glibc check that the version exists before loading for packages built by
boulder.
In Optimising Package Distribution we discussed some early
findings for implementing binary deltas in Serpent OS. While discussing the implementation we have found the
requirements to be suboptimal for what we were after. We provide a fresh look at the issue and what we can do to make it
useful in almost all situations without the drawbacks.
I remember back in the early 2000s on Gentoo when someone set up a server to produce delta patches from source tarballs
to distribute to users with small data caps such as myself. When requesting the delta, the job would be added to the
queue (which occasionally could be minutes) and then created a small patch to download. This was so important at the
time to reduce the download size that the extra time was well worth it!
Today things are quite different. The case for deltas has reduced for users as internet speeds have increased. Shrinking
20MB off a package size may be a second reduction for some, but 10 seconds for others. The largest issue is that deltas
have typically pushed extra computational effort onto the users computer in compensation for the smaller size. With a
fast internet connection that cost is a real burden where deltas take longer to install than simply downloading the full
package.
The previous idea of using the full payload for deltas was very efficient in terms of distribution, but required changes
in how moss handles packages to implement it. Having the previous payload available (and being fast) means storing the
old payloads on disk. This increases the storage requirements for the base system, although that can be reduced by
compressing the payloads to reduce disk usage (but increasing CPU usage at install time).
To make it work well, we needed the following requirements:
- Install all the files from a package and recreate the payload from the individual files. However, Smart System
Management allows users to avoid installing unneeded locale files and we would not be able to recreate the full
payload without them.
- Alternatively we can store the full payloads on disk. Then there becomes a tradeoff from doubling storage space or
additional overhead from compressing the payloads to reduce it.
- Significant memory requirements to use a delta when a package is large.
In short we weren't happy with having to increase the disk storage requirements (potentially more than 2x) or the
increase in CPU time to create compressed payloads to minimize it. This was akin to the old delta model, of smaller
downloads but significantly slower updates.
Optimal compression generally benefits from combining multiple files into one archive than to compress each file
individually. With zstd deltas, since you read in a dictionary (the old file), you already have good candidates for
compression matching. The real question was simply whether creating a delta for each file was a viable method for delta
distribution (packaged into a single payload of course).
As the real benefit of deltas is reducing download size, the first thing to consider is the size impact. Using the same
package as the previous blog post (but with newer versions of QtWebEngine and zstd) we look at what happens when you
delta each file individually. Note that the package is quite unique in that the largest file is 76% of the total package
size and that delta creation time increased a lot for files larger than 15-20MB at maximum compression.
Full Tarball
Individual Files
Full Tarball --zstd=chainLog=30
Individual Files --zstd=chainLog=30
Time to create
134.6s
137.6s
157.9s
150.9s
Size of delta
30.8MB
29.8MB
28.3MB
28.6MB
Peak Memory
1.77GB
1.64GB
4.77GB
2.64GB
Quite surprisingly, the delta sizes were very close! Most surprising was that without increasing the size of the
chainLog in zstd, the individual file approach actually resulted in smaller deltas! We can also see how much lower the
memory requirements were (and they would be much smaller when there isn't one large file in the package!). Our locale
and doc trimming of files will still work nicely, as we don't need to recreate the locale files that aren't installed
(as we still don't want them!).
The architecture of moss allows us to cache packages, where all cached packages are available for generating multiple
system roots including with our build tool boulder without any need for the original package file. Therefore any need
to retain old payloads or packages is no longer required or useful, eliminating the drawbacks of the previous delta
approach. The memory requirements are also reduced as the maximum memory requirement scales with the size of the largest
file, rather than the entire package (which is generally a lot bigger). There are many packages containing hundreds of
MBs of uncompressed data and a few into the GBs. But the largest file I could find installed locally was only 140MB, and
only a handful over 100MB. This smaller increase in memory requirements is a huge improvement and the small increase in
memory use to extract the deltas is likely to go unnoticed by users.
Well everything sounds pretty positive so far, there must be some drawback?
As the testing method for this article is quite simplistic (bash loops and calls to zstd directly), the additional
overhead from creating deltas for individual files I estimated to be about 20ms compared to a proper solution. The main
difference from the old delta method is how we extract the payloads and recreate the files of the new package. Using the
full package you simply extract the content payload and split it into its corresponding files. The new approach requires
two steps, extracting the payload (we could in theory not compress it) and then applying patches to the original files
to recreate the new ones. Note that times differ slightly from the previous table due to minor variations between test
runs.
Normal Package
Individual Delta File Package
Time to Delta Files
-
148.0s (137 files)
Time to Compress Payload
78.6s
4.0s
Size of Uncompressed Payload
165.8MB
28.9MB
Size of Compressed Payload
51.3MB
28.6MB
Instructions to Extract Payload
2,876.9m (349ms)
33.1m (34ms)
Instructions to Recreate Files
-
1,785.6m (452ms)
Total instructions to Extract
2,876.9m (349ms)
1,818.7m (486ms)
What's important to note is that is this reflects a worst case scenario for the delta approach, where all 137 files were
different between the old and new version of the package. Package updates where files remain unchanged allows us to omit
them from the delta package altogether! So the delta approach not only saves time downloading files, but also requires
fewer CPU instructions to apply the update. It's not quite a slam dunk though as reading the original file as a
dictionary results in an increase in elapsed time of extraction (though the extra time is likely much less than the time
saved downloading 20MB less!).
In Part 2 we will look at some ways we can tweak the approach to balance the needed resources for creating delta
packages and to reduce the time taken to apply them.
Note: This was intended to be a 2 part series as it contains a lot of information to digest.
However, Part 2 was committed and follows below.
There's more than one way to create a delta! This post follows on from the earlier analysis of creating some basic
delta packages. Where this approach, and the use of zstd, really thrives is that it gives us options in how to manage
the overhead, from creating the deltas to getting them installed locally. Next we explore some ideas of how we can
minimize the caching time of delta files.
To get the best bang for your buck with deltas, it is essential to reduce the size of the larger files. My experience in
testing was that there wasn't a significant benefit from creating deltas for small files. In this example, we only
create delta files when they are larger than a specific size while including the full version of files that are under
the cutoff. This reduces the number of delta files created without impacting the overall package size by much.
Only Delta Files Greater Than
Greater than 10KB
Greater than 100KB
Greater than 500KB
Time to Delta Files
146.1s (72 files)
146.3s (64 files)
139.4s (17 files)
Time to Compress Payload
3.9s
4.0s
8.3s
Size of Uncompressed Payload
28.9MB
29.3MB
42.4MB
Size of Compressed Payload
28.6MB
28.7MB
30.5MB
Instructions to Extract Payload
37.8m (36ms)
34.7m (29ms)
299.1m (66ms)
Instructions to Recreate Files
1,787.7m (411ms)
1,815.0m (406ms)
1,721.4m (368ms)
Total instructions to Extract
1,825.5m (447ms)
1,849.7m (435ms)
2,020.5m (434ms)
Here we see that by not creating deltas for files under 100KB, it barely impacts the size of the delta at all, while
reducing caching time by 50ms compared to creating a delta for every file (486ms from the previous blog post). It even
leads to up to a 36% reduction in CPU instructions to undertake caching through the delta than using the full package.
In terms of showing how effective this delta technique really is, I chose one of the worst examples and I would expect
that many deltas would be faster to cache when there's files that are exact matches between the old and new package. The
largest file alone took 300ms to apply the delta, where overheads tend to scale a lot when you start getting to larger
files.
There are also some steps we can take to make sure that caching a delta is almost always faster than the full package
(solving the only real drawback to users), only requiring Serpent OS resources to create these delta packages.
For this article, all the tests have been run with zstd --ultra -22 --zstd=chainLog=30...until now! The individual
file delta approach is more robust at lower compression levels to keep package size small while reducing how long they
take to create. Lets take a look at the difference while also ensuring --long is enabled. This testing combined with
the results above for only creating deltas for files larger than 10KB.
Individual Delta File Package
zstd -12
zstd -16
zstd -19
zstd -22
Time to Delta Files
6.7s
113.9s
142.3s
148.3s
Time to Compress Payload
0.5s
3.2s
5.3s
4.0s
Size of Uncompressed Payload
41.1MB
30.6MB
28.9MB
28.9MB
Size of Compressed Payload
40.9MB
30.3MB
28.6MB
28.6MB
Instructions to Extract Payload
46.5m (35ms)
51.2m (28ms)
42.6m (33ms)
37.8m (36ms)
Instructions to Recreate Files
1,773.7m (382ms)
1,641.5m (385ms)
1,804.2m (416ms)
1,810.9m (430ms)
Total instructions to Extract
1,820.2m (417ms)
1,692.7m (413ms)
1,846.8m (449ms)
1,848.7m (466ms)
Compression levels 16-19 look quite interesting where you start to reduce the time taken to apply the delta as well
and only seeing a small increase in size. For comparison, at -19 it only took 9s to delta the remaining 39.8MB of
files when excluding the largest file (it was 15s at -22). While the time taken between 19 and 22 was almost the same,
at -19 it took 27% fewer instructions to create the deltas than at -22 (-16 uses 64% fewer instructions than
-22). It will need testing across a broader range of packages to see the overall impact and to evaluate a sensible
default.
As a side effect of reducing the compression level, you also get another small decrease in the time to cache a package.
The best news of all is that these numbers are already out of date. Testing was performed last year with zstd 1.5.0,
where there have been notable speed improvements to both compression and decompression that have been included in newer
releases. Great news given how fast it is already! Here's a quick summary of how it all ties together.
This blog series has put forward a lot of data that might be difficult to digest...but what does it mean for users of
Serpent OS? Here's a quick summary of the advantages of using this delta method on individual files when compared to
fetching the full packages:
Package update sizes are greatly reduced to speed up fetching of package updates.
moss architecture means that we have no need to leave packages on disk for later use, reducing the storage
footprint. In fact, we could probably avoid writes (except for the extracted package of course!) by downloading
packages to tmpfs where you have sufficient free memory.
Delta's can be used for updating packages for packaging and your installed system. There's no need for a full
copy of the full original package for packaging. A great benefit when combined with the source repository.
Delta's are often overlooked due to being CPU intensive while most people have pretty decent internet speeds. This has
a lot to do with how they are implemented.
With the current vision for Serpent OS deltas they will require fewer CPU instructions to use than full packages, but
may slightly increase the time to cache some packages (but we are talking ms). But we haven't even considered the
reduction in time taken to download the delta vs the full package which more than makes up the difference!
The memory requirements are reduced compared to the prior delta approach, especially if you factor in extracting the
payload in memory (possibly using tmpfs) as part of installation.
There's still plenty more work to be done for implementing delta's in Serpent OS and they likely aren't that helpful
early on. To make delta packages sustainable and efficient over the long run, we can make them even better and reduce
some wastage. Here are some more ideas in how to make deltas less resource intensive and better for users:
As we delta each file individually, we could easily use two or more threads to speed up caching time. Using this
package as an example, two threads would reduce the caching time to 334ms, the time the largest file took to recreate
plus the time to extract the payload. Now the delta takes less time and CPU to cache than the full package!
zstd gives us options to tradeoff some increase in delta size to reduce the resources needed to create delta
packages. This testing was performed with --ultra -22 --zstd=chainLog=30 which is quite slow, but produces the
smallest files. Even reducing the compression level to -16 --long didn't result in a large increase in delta size.
We always have the option to not create deltas for small packages to ease the burden, but in reality the biggest
overhead is created from large files.
When creating deltas, you typically generate them for multiple prior releases. We can use smart criteria when to stop
delta generation from earlier releases for instance if they save less than 10% total size or less than 100KB. A delta
against an earlier release will almost always be larger than versus a more recent release.
While the numbers included have been nothing short of remarkable, they don't quite reflect how good this approach will
be. The results shown lack some of the key advantages of our delta approach such as excluding files that are unchanged
between the two packages. Other things that will show better results are:
When package updates include minimal changes between versions (and smaller files), we would expect the average package
to be much closer in elapsed time than indicated in these results.
A quick test using a delta of two package builds of the same source version resulted in a 13MB delta (rather than the
28.6MB delta we had here). On top of that it took 62% fewer CPU instructions and less time (295ms) than the full
package to extract (349ms) without resorting to multi-threading.
Delta creation of the average package will be quite fast where the largest files are <30MB. In our example, one file
is 76% of the package size (126MB) but can take nearly 95% of the total creation time!
We will be applying features to our packages that will reduce file sizes (such as the much smaller RELR relocations
and identical code folding), making the approach even better, but that will be for a future blog post.
One of the core steps for building a package is setting up a minimal environment with only the required (and stated)
dependencies. Currently we have been building our stones in an systemd-nspawn container, where the root contains every
package that's been built so far. This makes the environment extremely difficult to reproduce!
Today we announce moss-container, a simple but flexible container creator that we can integrate for proper
containerized builds.
Containers have a multitude of uses for a Linux distro, but our immediate use case is for reproducible container builds
for boulder. However, we have plans to use moss-container for testing, validation and benchmarking purposes as well.
Therefore it's important to consider all workloads, so features like fakeroot and networking can be toggled on or
off depending on what features are needed.
moss-container takes care of everything, the device nodes in the /dev tree, mounting directories as tmpfs so the
environment is left in a clean state, and mounting the /sys and /proc special file-systems. These are essential for
a fully functioning container where programs like python and even clang won't work without them. And best of all,
it's very fast so fits in well with the rest of our tooling!
The next step is integrating moss-container into boulder, so that builds become reproducible across machines, and
makes it much easier for users to run builds on their host machines.
Previously (but not covered in the blogs) work was also done on moss so that it can understand and fetch stone
packages from an online repo. This ties in nicely with the moss-container work and is a requirement for finishing up a
proper build process for Serpent OS. We are now one step closer to having a full distribution cycle from building
packages and pushing those packages as system updates!
In case you've missed it, ikey has been streaming some of the development of the tooling on his
Twitch channel. DLang is not as commonly used as other languages, so check it out
to see the advantages it brings. Streams are typically announced on twitter, or give him a follow to see when he next
goes live!
This year we've had a considerable number of new visitors and interest in Serpent OS. Unfortunately the content on the
website had been a bit stale and untouched for some time. There was some confusion and misunderstanding over some of the
terms and content. Some of the common issues were:
Subscriptions is a loaded term relating to software
Subscriptions only referred to a fraction of the smart features
Seemed targeted at advanced users with too many technical terms
Lack of understanding around what moss and boulder do
That features would add complexity when the tools were actually removing the complexity
The good news is that a good chunk of it has been redone, including two new pages for our core tools boulder and
moss. Subscriptions has been renamed to Smart System Management to reflect its broader nature (which you can read
about here).
Much of the content has also had a refresh or a rewrite, so if you've seen it before, it will likely be a lot easier to
digest now. But this isn't the final state of the content, as more features will need to be added and there's still a
few rough edges (and I like to rewrite things every once in awhile). Many ideas have been raised by our community in the
matrix channel, so a shout-out to the good folks we have hanging out there.