Squirrelling away in the background has been some great changes to bring boulder closer to its full potential. Here's
a quick recap of some of the more important ones.
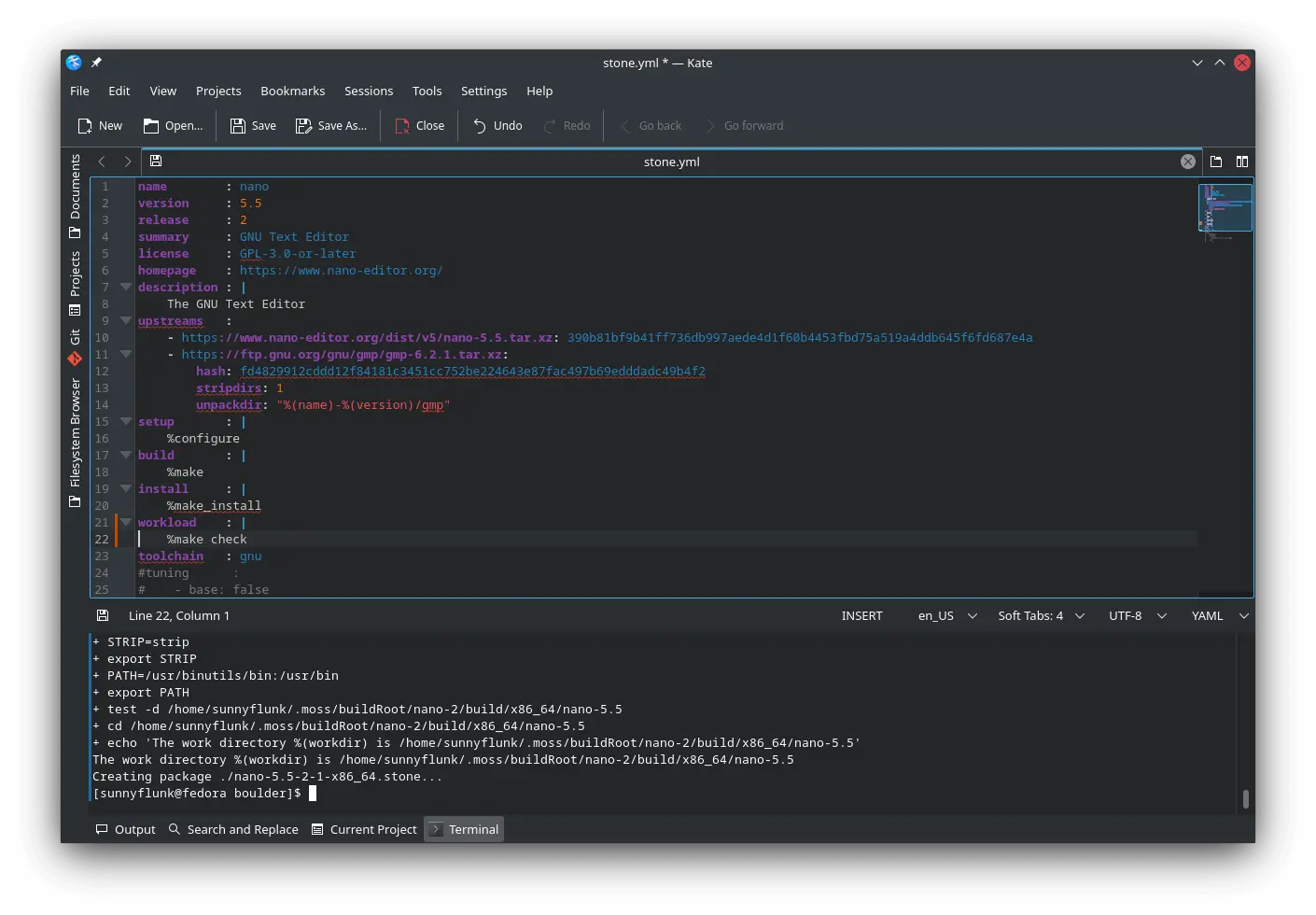
Fixed a path issue that prevented manifests from being written for 32bit builds
Added keys to control where the tarballs are extracted to
This results in a greatly simplified setup stage when using multiple upstreams
More customizations to control the final c{,xx}flags exported to the build
Added a key to run at the start of every stage so definitions can be exported easily in the stone.yml file
Fixed an issue where duplicate hash files were being included in the Content Payload
This resulted in reducing the Content Payload size by 750MB of a glibc build with duplicate locale files
Finishing touches on profile guided optimization (PGO) builds - including clang's context-sensitive PGO
Fixed a few typos in the macros to make it all work correctly
Profile flags are now added to the build stages
Added the llvm profile merge steps after running the workload
Recreate a clean working directory at the start of each PGO phase
With all this now in place, the build stages of boulder are close to completion. But don't worry, there's plenty more
great features to come to make building packages for Serpent OS simple, flexible and performant. Next steps will be testing
out these new features to see how much they can add to the overall stage4 performance.
We haven't been too great on sharing progress lately, so welcome to an overdue update on
timelines, progress, and database related shmexiness.
OK, so you may remember moss-format, our module for reading and writing moss binary archives.
It naturally contains much in the way of binary serialisation support, so we've extended the
format to support "database" files. In reality, they are more like tables binary encoded into
a single file, identified by a filepath.
The DB archives are currently stored without compression to ensure 0-copy mmap() access
when loading from disk, as a premature optimisation. This may change in future if we find the
DB files taking up too much disk space.
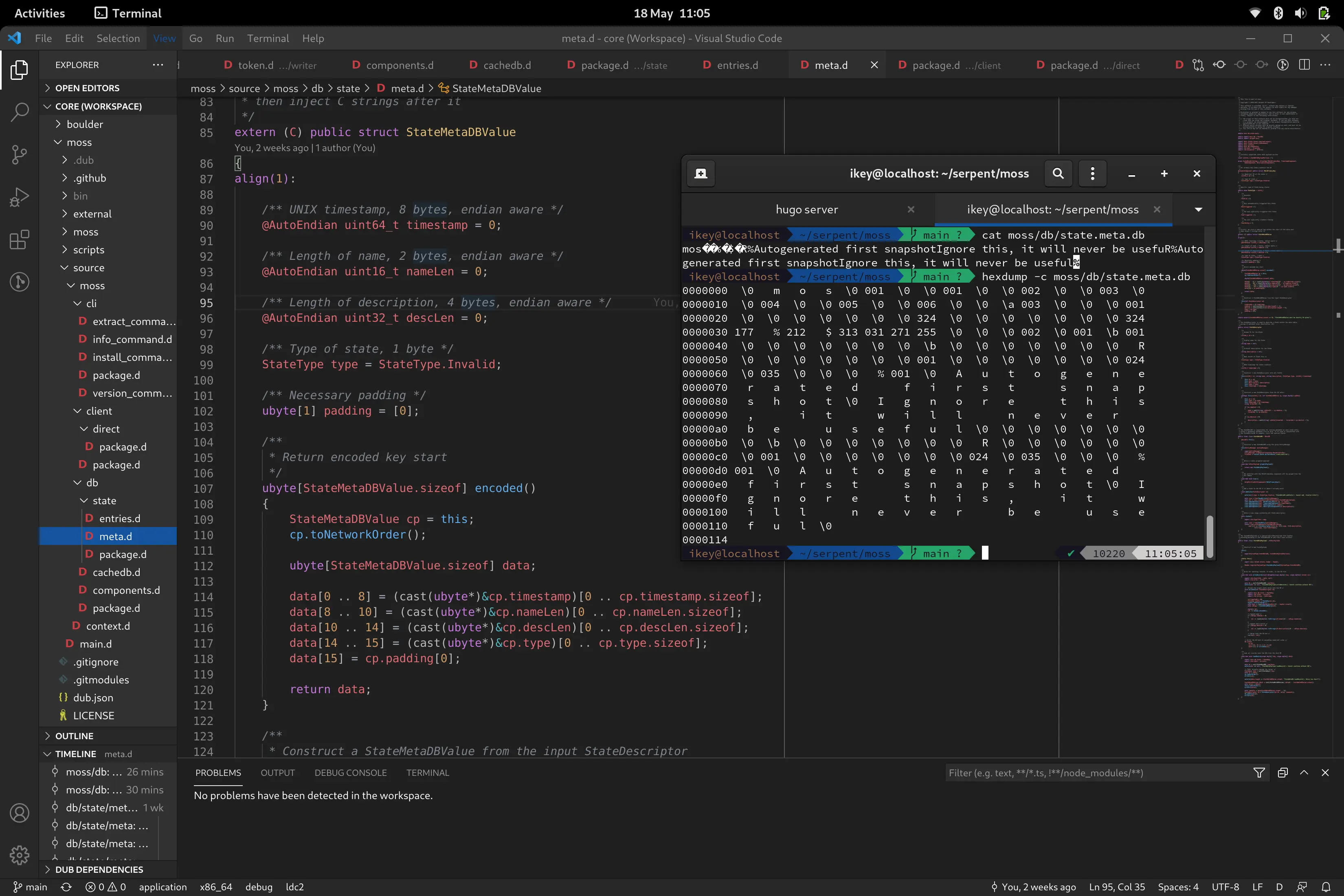
So far we've implemented a "StateMetaDB", which stores metadata on every recorded State on
the system, and right now I'm in the progress of implementing the "StateEntriesDB", which is
something akin to a binary encoded dpkg selections file with candidate specification reasons.
Next on the list is the LayoutsDB (file manifests) and the CacheDB, for recording refcounts
of every cached file in the OS pool.
An interesting trial we're currently implementing is to hook the DB implementation up to
our Entity Component system from the Serpent Engine, in order to provide fast, cache coherent,
in memory storage for the DB. It's implemented using many nice DLang idioms, allowing the full
use of std.algorithm APIs:
autostates(){importstd.algorithm:map;autoview=View!ReadOnly(entityManager);returnview.withComponents!StateMetaArchetype.map!((t)=>StateDescriptor(t[1].id,t[3].name,t[4].description,t[1].type,t[2].timestamp));}.../* Write the DB back in ascending numerical order */db.states.array.sort!((a,b)=>a.id<b.id).each!((s)=>writeOne(s));
Ok, so you can see we need basic DB types for storing the files for each moss archive, plus each
cache and state entry. If you look at the ECS code above, it becomes quite easy to imagine how this
will impact installation of archives. Our new install code will simply modify the existing state,
cache the incoming package, and apply the layout from the DB to disk, before committing the new
DB state.
In essence, our DB work is the current complex target, and installation is a <50 line trick
tying it all together.
/* Psuedocode */StatenewState...foreach(pkgID;currentState.filter!((s)=>s.reason==SelectionReason.Explicit)){autofileSet=layoutDB.get(pkgID);fileSet.array.sort!((a,b)=>a.path<b.path).each!((f)=>applyLayout(f));/* Record into new state */...}
Well, it's not all doom and gloom these days. We've actually made some
significant progress in the last few days, so it seems a good time to
share a progress update.
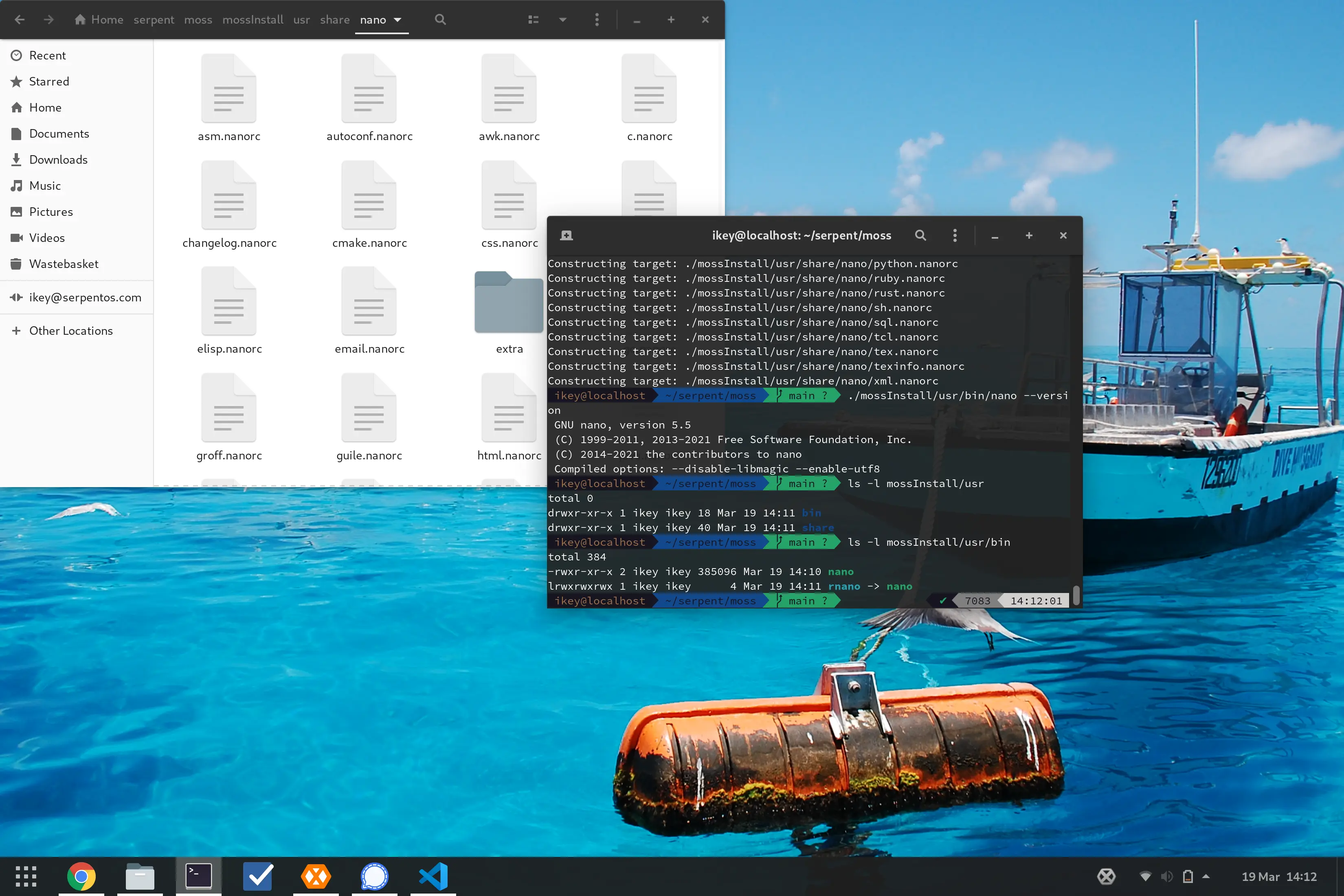
Oh yeah, that totally happened. So, we can now successfully build moss
packages from boulder and then extract them to disk once again with
moss. This might sound totally uninteresting, but it demonstrates
that our format is actually working as intended.
Admittedly the code is super rough within moss and somewhat proof
of concept, however we're able to extract the contents of the moss
archive and rebuild the layout on disk.
Well, quirky new format for one. A moss archive currently consists of
4 "payloads", or major sections:
MetaPayload
Contains all package information, with strongly typed keys.
IndexPayload
Contains the IDs of all unique files (hash) and their offsets within
the ContentPayload
LayoutPayload
A sequence of specialised structs describing the final "layout" of the
package on disk, with attributes, paths, and for regular files, the ID
of the file in the ContentPayload to build this file from.
ContentPayload
A binary blob containing every unique file from the package, in an order
described by the IndexPayload. The files are stored sequentially with
no gaps.
Additionally, each payload is independently compressed using zstd. In order
to extract files to disk, we must first decompress ContentPayload to a
temporary file. Next, we blit each file from the "megablob" to the cache store,
using the IndexPayload to understand the offsets. Finally, we apply the
instructions in LayoutPayload to construct the final layout on disk, hardlinking
the cache assets into their final locations, setting attributes, etc.
Net result? Deduplication on a per package basis, and a system-wide deduplication
policy allowing sharing of identical assets on disk between multiple packages.
This will also power our core update mechanism, whereby each update is atomic,
and is simply the difference on disk from the previous version, permitting a
powerful rollback mechanism.
There are areas where we're doing things inefficiently, and we'll certainly improve
that in future revisions of the important. For example, IndexPayload actually
wastes some bytes by storing redundant information that can be calculated at
runtime. Additionally, we want to use the zstd C APIs directly to gain the level
of control we actually need. We're also going to wrap the copy_file_range
syscall to make extraction of the content payload more efficient and not rely on
userspace copies.
However, we're working towards a prealpha, and some inefficiencies are OK. Our
first port of call will be a prealpha image constructed from .stone files, produced
by boulder, installed by moss. This will validate our toolchain and tooling
and serve as a jumping off point for the project.
Stay tuned, there is a whole bunch of awesome coming now that moss is officially
unlocked and progressing.
I want to thank everyone who is currently supporting the project. I also want to personally
thank you for your understanding of the setbacks of real life, given the difficult times myself
and my family have been going through. I hope it is clear that I remain committed to the
project and it's future, which is why we're transparently run and funded via OpenCollective.
Despite the rough times, work continues, and awesome people join our ranks on a regular basis.
Stability is on the immediate horizon and work with Serpent OS grows exponentially. You can
be part of our journey, and help us build an amazing community and project that outlives us
all.
Getting updates as fast as possible to users has made deltas a popular and sought after feature for distributing
packages. Over the last couple of days, I've been investigating various techniques we can look at to support deltas in
moss.
Minimising the size of updates is particularly valuable where files are downloaded many times and even better if they're
updated infrequently. With a rolling release, packages will be updated frequently, so creating deltas can become
resource intensive, especially if supporting updates over a longer period of time. Therefore it's important to get the
right balance between compression speed, decompression memory and minimising file size.
Package priorities
How best to meet these needs
Developers
Creation speed
Quickly created packages
Users
File size and update speed
Size minimised deltas
From the users point of view, minimising file size and upgrade time are important priorities, but for a developer, the
speed at which packages are created and indexed is vital to progression. Deltas are different to packages in that they
aren't required immediately, so there's minimal impact in taking longer to minimise their size. By getting deltas right,
we can trade-off the size of packages to speed up development, while users will not be affected and fetch only size
optimised deltas.
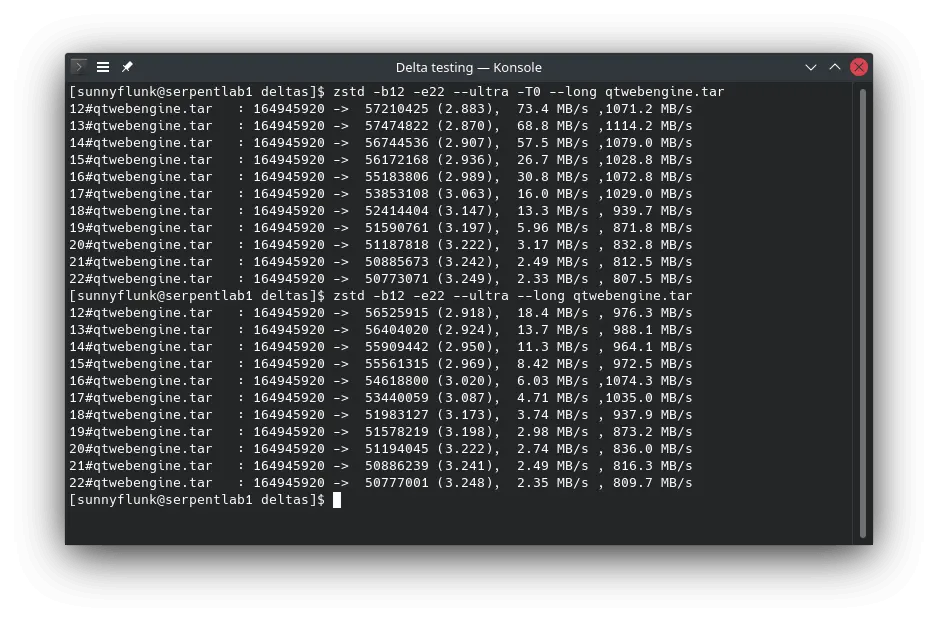
QtWebEngine provides a reasonable test case where the package is a mix of binaries, resources and translations, but
above average in size (157.3MB uncompressed). The first trade-off for speed over size has already been made by
incorporating zstd in moss over xz, where even with max compression zstd is already 5.6% larger than using xz.
This is of course due to the amazing decompression speeds where zstd is magnitudes faster.
With maximum compression, large packages can take over a minute to compress. With a moderate increase in size, one can
reduce compression time by 2-10x. While making me happier as a developer, it does create extra network load during
updates.
There are two basic methods for deltas. One simple method is to include only files that have been changed since the
earlier release. With reproducible builds, it is typical to create the same file from the same inputs. However, with a
rolling release model, files will frequently have a small change from dependency changes and new versions of the package
itself. In these circumstances the delta size starts to get closer to the full package anyway. As a comparison to other
delta techniques, this approach resulted in a 38.2MB delta as it was a rebuild of the same version at a different time
so the resources and translations were unchanged (and therefore omitted from the delta).
An alternative is a binary diff, which is a significant improvement when files have small changes between releases.
bsdiff has long been used for this purpose and trying it out (without knowing much about it) I managed to create a
delta of 33.2MB, not a bad start at all.
To highlight the weakness of the simple method, when you compare the delta across a version change, the simple delta was
only a 7% reduction of the full package (as most files have changed), while using an optimal binary diff, it still
managed to achieve a respectable 31% size reduction.
While looking into alternatives, I happened to stumble across
a new feature in zstd which can be used to create deltas. As we already use zstd heavily it should make integration
easier. --patch-from allows zstd to use the old uncompressed package as a dictionary to create the newer package. In
this way common parts between the releases will be reused in order to reduce the file size. Playing around I quickly
achieved the same size as bsdiff, and with a few tweaks was able to further reduce the delta by a further 23.5%!
The best part is that it has the same speedy decompression as zstd, so it will recreate most packages from deltas in
the blink of an eye!
There's certainly a lot of information to digest, but the next step is to integrate a robust delta solution into the
moss format. I really like the zstd approach, where you can tune for speed with an increase in size if desired. With
minimising on delta size, users can benefit from smaller updates while developers can benefit from faster package
creation times.
Some final thoughts for future consideration:
zstd has seen many improvements over the years, so I believe that ratios and performance will see incremental
improvements over time. Release 1.4.7 already brought
significant improvements to deltas (which are reflected in this testing).
The highest compression levels (--ultra) are single threaded in zstd, so delta creation can be done in parallel to
maximise utilisation.
Over optimising the tunables can have a negative impact on both speed and size. As an example,
--zstd=targetLength=4096 did result in a 2KB reduction in size at the same speed, but when applied to different inputs
(kernel source tree), it not only made it larger by a few hundred bytes, but added 4 minutes to delta creation!
Memory usage of applying deltas can be high for large packages (1.74GB for the kernel source tree) as it has to ingest
the full size of the original uncompressed package. It is certainly possible to split up payloads with some delta users
even creating patches on a per file basis. It is a bit more complicated when library names change version numbers each
release with only the SONAME symlink remaining unchanged.
There's always the option to repack packages at higher compression levels later (when deltas are created). This solves
getting the package 'live' ASAP and minimises the size (eventually), but adds some complication.
It's been 8 days since our last blogpost and a lot of development work has happened
in that time. Specifically, we've completely reworked the internals of the moss-format
module to support read/write operations.. Which means installation is coming soon (TM)
So, many commits have been made to the core repositories, however the most
important project to focus on right now is moss-format, which we used to
define and implement our binary and source formats. This module is shared
between boulder, our build tool, and moss, our package manager.
We've removed the old enumeration approach from the Reader class, instead
requiring that it processes data payloads in-place, deferring reading the
content payload streams. We've also enforced strong typing to allow
safe and powerful APIs:
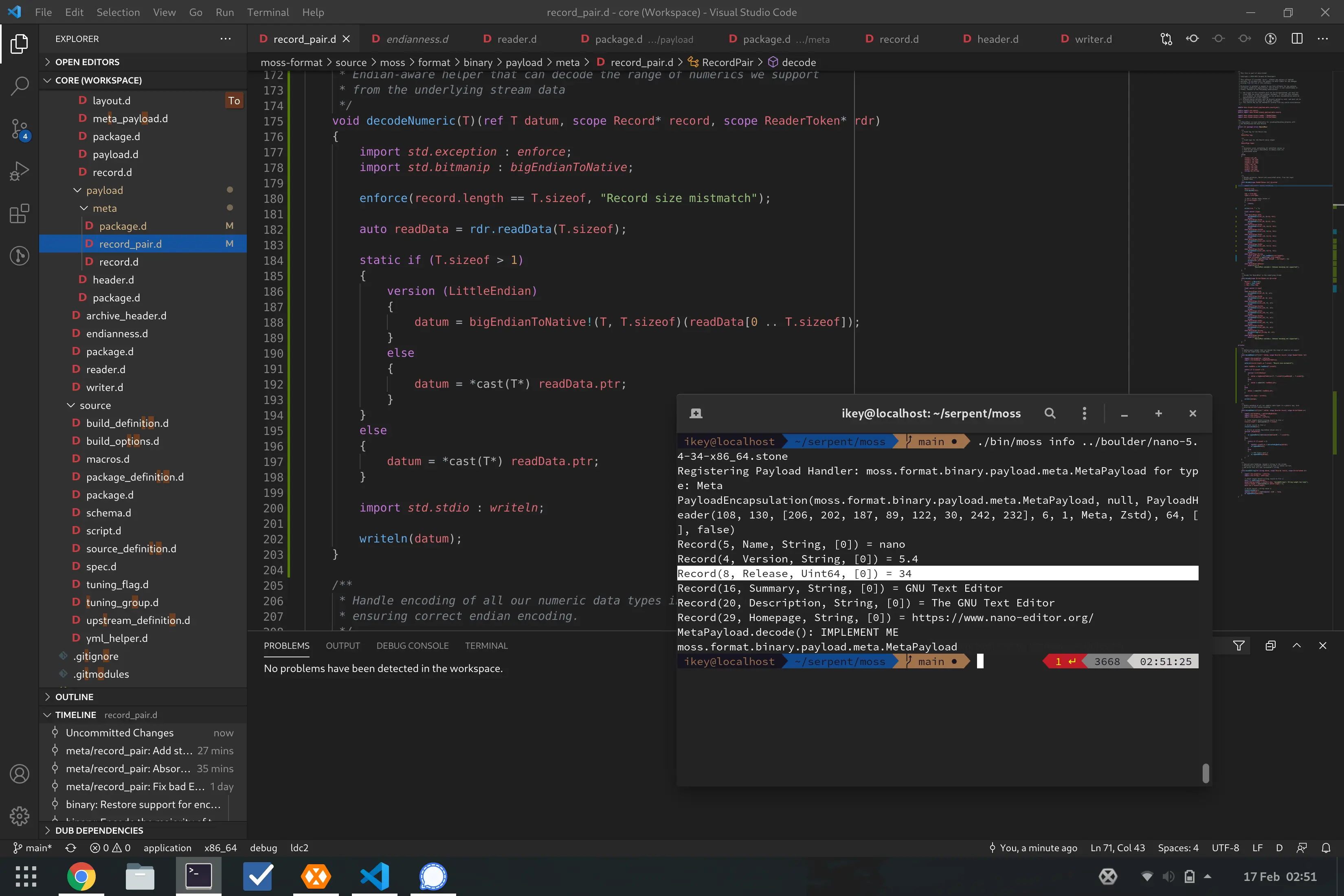
Right now we can read and write our MetaPayload from and to the stream,
allowing us to encode & decode the metadata associated with the package,
with strong type information (i.e. Uint64, String, etc.)
We need to restore the IndexPayload, LayoutPayload and ContentPayload
definitions. The first two are simply data payloads and will largely
follow the design of the newly reimplemented MetaPayload. Then we restore
ContentPayload support, and this will allow the next steps: unpack, install.
Many of the babysteps required are done now, which power our binary format.
The design of the API is done in a way which will allow powerful manipulation
via the std.algorithm and std.range APIs, enabling extremely simple and
reliable installation routines.
It might seem odd that we've spent so much time on the core format,
however I should point out that the design of the format is central to the
OS design. Our installation routine is not unpacking of an archive.
With our binary format, the stream contains multiple PayloadHeaders,
with fixed lengths, type, tag, version, and compression information.
It is up to each Payload implementation to then parse the binary
data contained within. Currently our Payloads are compressed using ZSTD, though
other compression algorithms are supported.
So, we have the MetaPayload for metadata. Additionally, we encode all unique
files in the package in a single compressed payload, the ContentPayload. The
offset to each unique file (by hash) is stored within the IndexPayload, and
the filesystem layout is encoded as data within the LayoutPayload.
In order to unpack a moss package, the ContentPayload blob will be decompressed
to a temporary location. Then, each struct within the IndexPayload can be used
to copy portions (copy_file_range) of the blob to the cache store for permanence. We skip each Index
if its already present within the cache. Finally, the target filesystem is populated
with a view of all installed packages using the LayoutPayload structs, creating
a shallow installation using hardlinks and directories.
The net result is deep deduplication, atomic updates, and flexibility for the user.
Once we add transactions it'll be possible to boot an older version of the OS using
the deduplication capabilities for offline recovery. Additionally there is no requirement
for file deletion, rename or modification for an update to succeed.
Wait, what? Another blog post? In the same WEEK? Yeah totally doing that
now. So, this is just another devlog update but there have been some interesting
updates that we'd like to share.
Thanks to some awesome work from Peter, we now have LDC (The LLVM D Lang Compiler)
present in the stage3 bootstrap. To simplify the process we use the official
binary release of LDC to bootstrap LDC for Serpent OS.
In turn, this has allowed us to get to a point where we can now build moss and
boulder within stage3. This is super important, as we'll use the stage3 chroot
and boulder to produce the binary packages that create stage4.
Some patching has taken place to prevent using ld.gold and instead use lld
to integrate with our toolchain decisions.
Originally our prototype moss format only contained a ContentPayload for files, and
a MetaPayload for metadata, package information, etc. As a result, we opted for simple
structs, basic case handling and an iterable Reader implementation.
As the format expanded, we bolted deduplication in as a core feature. To achieve this,
we converted the ContentPayload into a "megablob", i.e. every unique file in the
package, one after the other, all compressed in one operation. We then store the offsets
and IDs of these files within an IndexPayload to allow splitting the "megablob" into
separate, unique assets. Consequently, we added a LayoutPayload which describes the
final file system layout of the package, referencing the unique ID (hash) of the asset
to install.
So, while the format grew into something we liked, the code supporting it became very
limiting. After many internal debates and discussions, we're going to approach the
format from a different angle on the code front.
It will no longer be necessary/possible to iterate payloads in sequence within a
moss archive, instead we'll preload the data (unparsed) and stick it aside when reading
the file, winding it to the ContentPayload segment if found. After initial loading of
the file is complete, the Reader API will support retrieval (and lazy unpacking ) of
a data segment. In turn this will allow code to "grab" the content, index and layout
payloads and use advanced APIs to cache assets, and apply them to disk in a single
blit operation.
In short, we've unlocked the path to installing moss packages while preserving the
advanced features of the format. The same new APIs will permit introspection of the
archives metadata, and of course, storing these records in a stateful system database.
Oh you're quite welcome :P Hopefully now you can see our plan, and that we're on track
to meet our not-28th target. Sure, some code needs throwing away, but all codebases
are evolutionary. Our major hurdle has been solved (mentally) - now it's just time
to implement it and let the good times roll.
Well, we're officially back to working around the clock. After spending
some time optimising my workflow, I've been busy getting the entire codebase
cleaned up, so we can begin working towards an MVP.
Since Friday, I've been working extensively on cleaning up the codebase for the
following projects:
boulder
moss
moss-core
moss-format
As it now stands, 1 lint issue (a non-issue, really) exists across all 4
projects. A plethora of issues have been resolved, ranging from endian correctness
in the format to correct idiomatic D-lang integration and module naming.
Granted, cleanups aren't all that sexy. Peter has been updating many parts of
the bootstrap project, introducing systemd 247.3, LLVM 11.0.1, etc. We now have
all 3 stages building correctly again for the x86_64 target.
Yikes, tough audience! So we've formed a new working TODO which will make its
way online as a public document at some point. The first stage, cleanups, is
done. Next is to restore feature development, working specifically on the
extraction and install routines. From there, much work and cadence will be
unlocked, allowing us to work towards an MVP.
I know, it makes me feel all ... cute and professional. At the moment we're cooking up
a high level description of how an MVP demonstration could be deployed. While most of
the features are ambiguous, our current ambition is to deploy a preinstalled QCOW2
Serpent OS image as a prealpha to help validate moss/boulder/etc.
It'll be ugly. Likely slow. Probably insecure as all hell. But it'll be something.
It'll allow super basic interaction with moss, and a small collection of utilities that
can be used in a terminal environment. No display whatsoever. That can come in a future
iteration :)
ETA? Definitely not by the 28th of February. When it's done.