Well, it's not all doom and gloom these days. We've actually made some significant progress in the last few days, so it seems a good time to share a progress update.
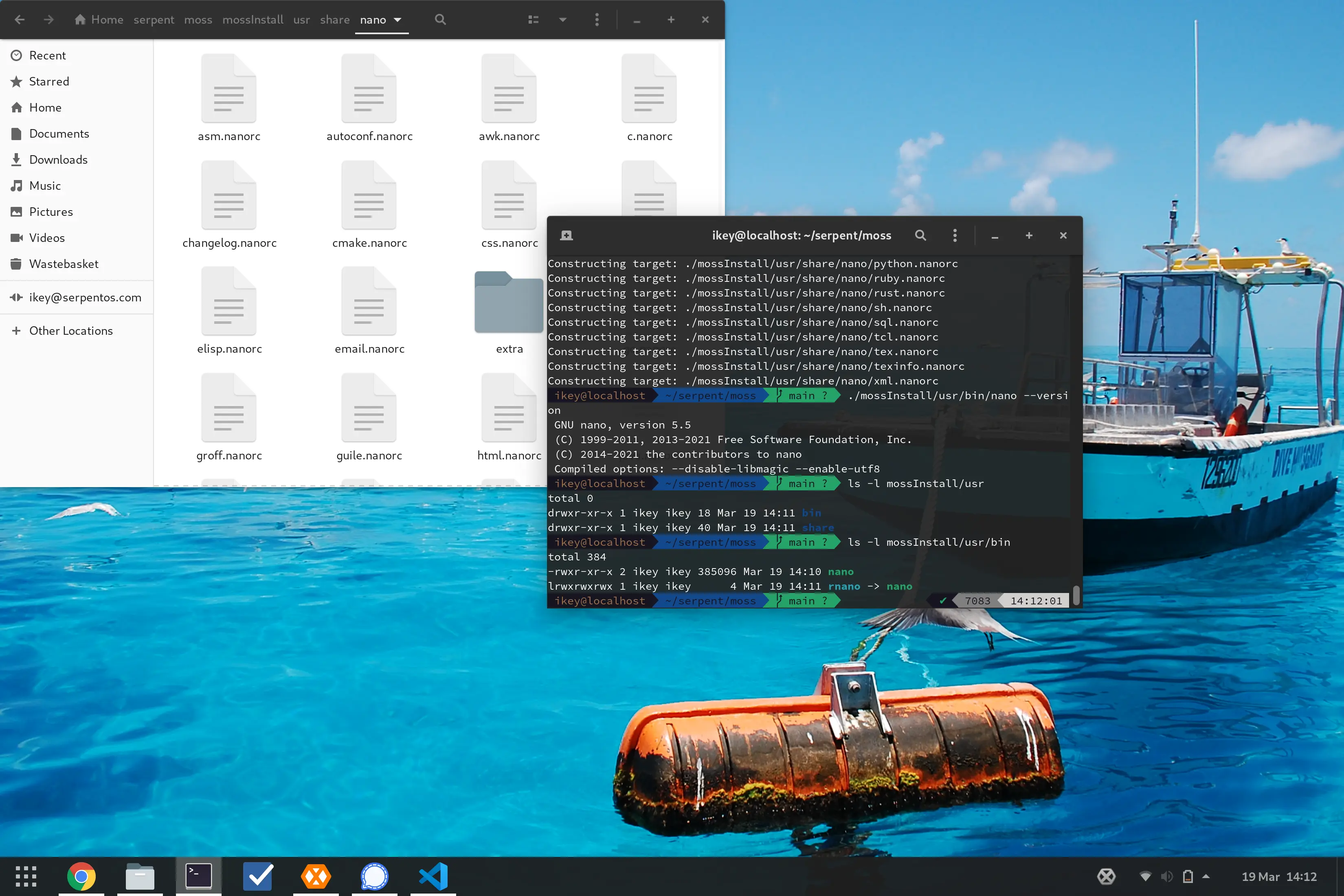
moss can now extract
Oh yeah, that totally happened. So, we can now successfully build moss
packages from boulder and then extract them to disk once again with
moss. This might sound totally uninteresting, but it demonstrates
that our format is actually working as intended.
Admittedly the code is super rough within moss and somewhat proof
of concept, however we're able to extract the contents of the moss
archive and rebuild the layout on disk.
What makes extraction difficult?
Well, quirky new format for one. A moss archive currently consists of 4 "payloads", or major sections:
-
MetaPayloadContains all package information, with strongly typed keys.
-
IndexPayloadContains the IDs of all unique files (hash) and their offsets within the ContentPayload
-
LayoutPayloadA sequence of specialised structs describing the final "layout" of the package on disk, with attributes, paths, and for regular files, the ID of the file in the ContentPayload to build this file from.
-
ContentPayloadA binary blob containing every unique file from the package, in an order described by the
IndexPayload. The files are stored sequentially with no gaps.
Additionally, each payload is independently compressed using zstd. In order
to extract files to disk, we must first decompress ContentPayload to a
temporary file. Next, we blit each file from the "megablob" to the cache store,
using the IndexPayload to understand the offsets. Finally, we apply the
instructions in LayoutPayload to construct the final layout on disk, hardlinking
the cache assets into their final locations, setting attributes, etc.
Net result? Deduplication on a per package basis, and a system-wide deduplication policy allowing sharing of identical assets on disk between multiple packages. This will also power our core update mechanism, whereby each update is atomic, and is simply the difference on disk from the previous version, permitting a powerful rollback mechanism.
Room for improvement

There are areas where we're doing things inefficiently, and we'll certainly improve
that in future revisions of the important. For example, IndexPayload actually
wastes some bytes by storing redundant information that can be calculated at
runtime. Additionally, we want to use the zstd C APIs directly to gain the level
of control we actually need. We're also going to wrap the copy_file_range
syscall to make extraction of the content payload more efficient and not rely on
userspace copies.
However, we're working towards a prealpha, and some inefficiencies are OK. Our
first port of call will be a prealpha image constructed from .stone files, produced
by boulder, installed by moss. This will validate our toolchain and tooling
and serve as a jumping off point for the project.
Stay tuned, there is a whole bunch of awesome coming now that moss is officially unlocked and progressing.
And finally
I want to thank everyone who is currently supporting the project. I also want to personally thank you for your understanding of the setbacks of real life, given the difficult times myself and my family have been going through. I hope it is clear that I remain committed to the project and it's future, which is why we're transparently run and funded via OpenCollective.
Despite the rough times, work continues, and awesome people join our ranks on a regular basis. Stability is on the immediate horizon and work with Serpent OS grows exponentially. You can be part of our journey, and help us build an amazing community and project that outlives us all.