Optimal File Locality
File locality in this post refers to the order of files in our content payload. Yes that's right, we're focused on the
small details and incremental improvements that combined add up to significant benefits! All of this came about from
testing the efficiency of content payload in moss-format and how well it compared against a plain tarball. One day
boulder was looking extremely inefficient and then retesting the following day was proving to be extremely efficient
without any changes made to boulder or moss-format. What on Earth was going on?
Making Sure you Aren't Going Crazy!
To test the efficiency our content payload, the natural choice was to compare it to a tarball containing the same files. When first running the test the results were quite frankly awful! Our payload was 10% larger than the equivalent tarball! It was almost unbelievable in a way, so the following day I repeated the test again only this time the content payload was smaller than the tarball. This didn't actually make sense, I made the tarball with the same files, but only changed the directory it was created from. Does it really matter?
File Locality Really Matters!
Of course it does (otherwise it would be a pretty crappy blog post!). When extracting a .stone package it creates two
directories, mossExtract where the sha256sum named files are stored and mossInstall where those files are
hardlinked to their full path name. The first day I created the tarball from mossInstall and the second day I
realised that creating the tarball from mossExtract would provide the closest match to the content payload since it
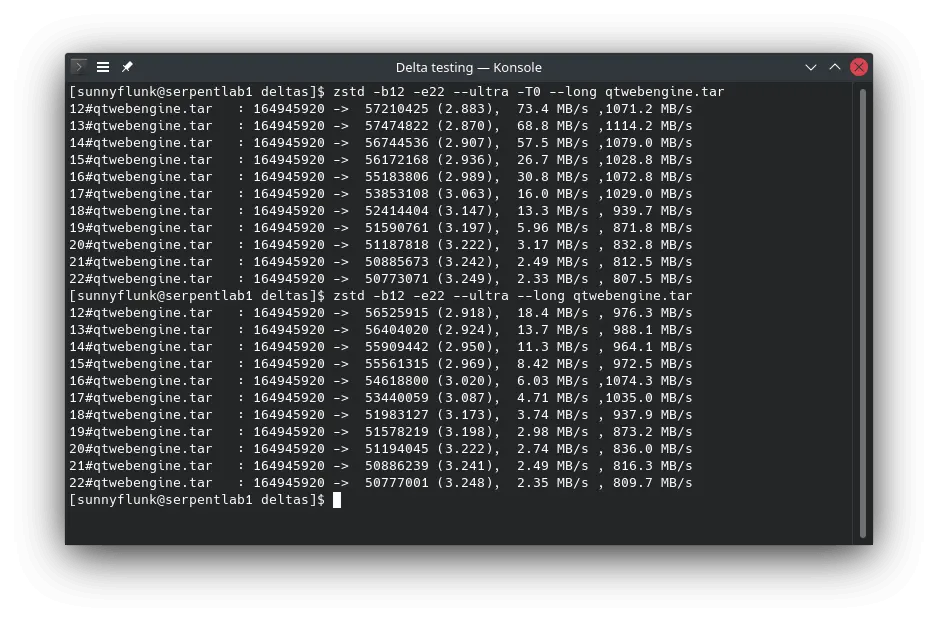
was a direct comparison. When compressing the tarballs to match the .stone compression level, the tarball compressed
from mossInstall was 10% smaller, despite the uncompressed tarball being slightly larger.
Compression Wants to Separate Apples and Oranges
In simplistic terms, the way compression works is comparing data that it's currently reading versus data that it's read
earlier in the file. zstd has some great options like --long that increases the distance in which these matches can
be made at the cost of increased memory use. To limit memory use while making compression and decompression fast, it
takes shortcuts that reduce the compression ratio. For optimal compression, you want files that are most similar to
each other to be as close as possible. You won't get as many matches from a text file to an ELF file as you would from a
similar looking text file.
Spot the Difference
Files in mossExtract are listed in their sha256sum order, which is basically random, where files in mossInstall are
ordered by their path. Sorting files by path actually does some semblance of sorting where binaries are in /usr/bin
and libraries are in /usr/lib bringing them closer together. This is in no way a perfect order, but is a large
improvement on a random order (up to 10% in our case!).
Our glibc package has been an interesting test case for boulder, where an uncompressed tarball of the install
directory was just under 1GB. As boulder stores files by their sha256sum, it is able to deduplicate files that
are the same even when the build hasn't used symlinks or hardlinks to prevent the wasted space. In this case, the
deduplication reduced the uncompressed size of the payload by 750MB alone (that's a lot of duplicate locale data!). In
the python package, it removes 1,870 duplicate cache files to reduce the installation size.
As part of the deduplication process boulder would sort files by sha256sum to remove duplicate hashes. If two files
have the same sha256sum, then only one copy needs to be stored. It also felt clean with the output of moss info
looking nice where the hashes are listed in alphabetical order. But it was having a significant negative impact on
package sizes so that needed to be addressed by resorting the files by path order (a simple one-liner), making the
content payload more efficient than a tarball once again.
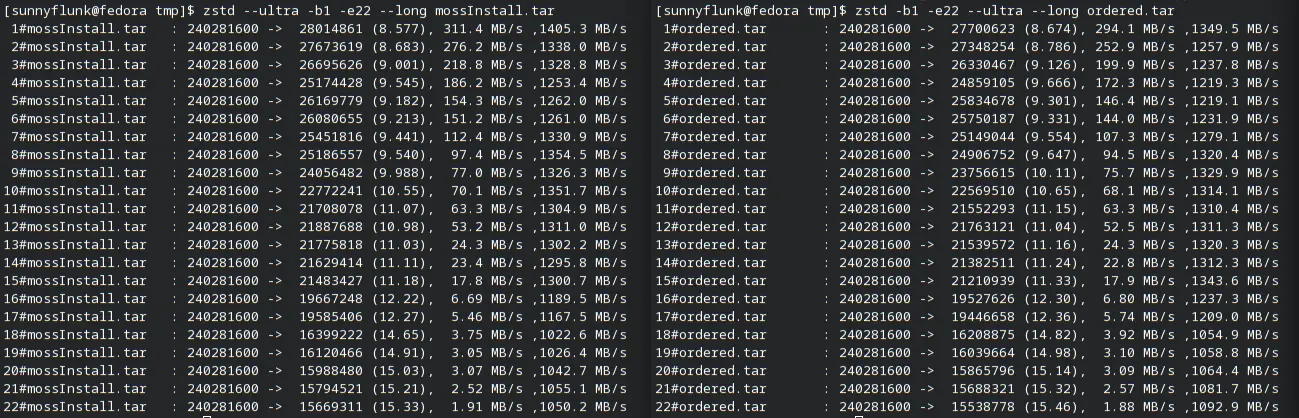
| Compression Level | sha256sum Order | File path Order |
|---|---|---|
| 1 | 72,724,389 | 70,924,858 |
| 6 | 65,544,322 | 63,372,056 |
| 12 | 49,066,505 | 44,039,782 |
| 16 | 45,365,415 | 40,785,385 |
| 19 | 26,643,334 | 24,134,820 |
| 22 | 16,013,048 | 15,504,806 |
Testing has shown that higher compression levels (and enabling --long) is more forgiving of a suboptimal file order
(3-11% smaller vs only 2-5% smaller when using --long). The table above is without --long so the difference is
larger.
Hang On, Why Don't You...
There's certainly something to this and sorting by file order is a first step. In future we can consider creating an
efficient order for files to improve locality. Putting all the ELF, image or text files together in the payload will
help to shave a bit off our package sizes at only the cost to sort the files. However, we don't want to go crazy here,
the biggest impact on reducing package sizes will be using deltas as the optimal package delivery system (and there will
be a followup on this approach shortly). The moss-format content payload is quite simple and contains no filenames or
paths in it. Therefore it's effectively costless to switch around the order of files, so we can try out a few things and
see what happens.
An Academic Experiment
To prove the value of moss-format and the content payload, I tried out some crude sorting methods and their impact on
compression for the package. As you want similar files chunked together, it divided the files into 4 groups, still
sorted by their path order in their corresponding chunk:
- gz: gzipped files
- data: non-text files that weren't ELF
- elf: ELF files
- text: text files (bash scripts, perl etc)
As the chart shows, you can get some decent improvements from reordering files within the tarball when grouping files in logical chunks. At the highest compression level, the package is reduced by 0.83% without any impact on compression or decompression time. In the compression world, such a change would be greatly celebrated!
Also important to note was that just moving the gzipped files to the front of the payload was able to capture 40% of the size improvement at high compression levels, but had slightly worse compression at levels 1-4. So simple changes to the order (in this case moving non-compressible files to the edge of the payload) can provide a reduction in size at the higher levels that we care about. We don't want to spend a long time analyzing files for a small reduction in package size, so we can start off with some basic concepts like this. Moving files that don't compress a lot such as already compressed files, images and video to the start of payload meaning that the remaining files are closer together. We also need to test out a broader range of packages and the impact any changes would have on them.
Food For Thought?
So ultimately the answer to the original question (was moss-format efficient?), the answer is yes! While there are
some things that we still want to change to make it even better, in its current state package creation time was faster
and overheads were lower than with compressing an equivalent tarball. The compressed tarball at zstd -16 was 700KB
larger than the full .stone file (which contains a bit more data than the tarball).
The unique format also proves its worth in that we can make further adjustments to increase performance, reduce memory requirements and reduce package sizes. What this experiment shows is that file order really does matter, but using the basic sorting method of filepath gets you most of the way there and is likely good enough for most cases.
Here are some questions we can explore in future to see whether there's greater value in tweaking the file order:
- Do we sort ELF files by path order, file name or by size?
- Does it matter the order of chunks in the file? (i.e. ELF-Images-Text vs Images-Text-ELF)
- How many categories do we need to segregate and order?
- Can we sort by extension? (i.e. for images, all the png files will be together and the jpegs together)
- Do we simply make a couple of obvious changes to order and leave
zstdto do the heavy lifting?